
NBJL 2020论文导读27: Read as Needed: Building WiSER,a Flash-Optimized Search Engine
论文(以及slide)下载地址:https://www.usenix.org/conference/fast20/presentation/he
论文信息: 论文发表于FAST2020,作者为Jun He and Kan Wu, University of Wisconsin—Madison; Sudarsun Kannan,Rutgers University; Andrea Arpaci-Dusseau and Remzi Arpaci-Dusseau, University of Wisconsin。
论文摘要
本文提出了 “按需读取”的搜索引擎——WISER,利用多种技术,以相对较少的内存提高吞吐和降低延迟,这些技术包括优化的数据布局、双向的成本感知的bloom filter、自适应预取和时空权衡。
本文是基于Elasticsearch(ES)进行的一系列优化,ES是被广泛应用的搜索和数据分析引擎,为了提高效率,ES把所有索引数据都放在内存,但随着互联网数据的剧增,数据都放在内存会产生非常昂贵的成本。现代固态存储设备(ssd)比传统的持久存储(如硬盘驱动器(HDDs))提供更高的吞吐量和更低的延迟,所以本文考虑利用ssd这个快速设备上实现按需读取的搜索引擎,只应用比较小的内存来实现高的吞吐和低延迟。
实验证明。WISER比最先进的ES减少了3倍读放大,增加高达2.7倍的查询吞吐,延迟降低高达16倍。
论文内容
技术描述
ES主要存在读放大问题,针对读放大,WISER主要有一下四种优化。
跨阶段数据分组
搜索引擎的搜索过程中的数据主要分为4个阶段:先获取文档编号(docid),再获取词频(tf)进行算分,如果是短语查询再获取位置信息,最后获取词的偏移进行摘要生成。ES的数据是按阶段将数据分组,这样将数据分成三组,如图1。但这样会造成读放大,如果某个查询的总索引数据量为30字节,如果按这种数据分组,在WISER中需要3次IO,读出12KB的数据,所以本文用了按term组织数据,让数据更紧凑如图2所示,以减小尤其是小中型链表的读放大。维基百科99%链表是小中型,而且大的链表也经常被拆分开,那么维基百科数据至少99%的链可以存储在一个块中,一次IO取出,显著减小了读放大。
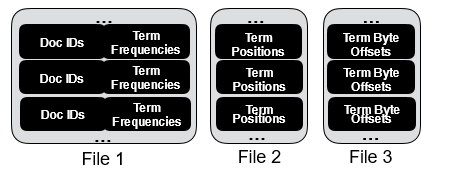
图1 ES数据分组

图2 WISER数据分组
在ES中布隆过滤器主要是用于短语查询例如“United States”,用于表示一个States是否在另一个United的后面,在ES中短语查询分为两步,a通过布隆过滤器查询某篇文档中“States“是否在”United“后面,b为了防止是假阳性,读取位置索引进行验证。由于位置索引是压缩的。如果直接应用ES里原有的bloom filter,会产生很多IO,主要是两个方面bloom filter很大有时还不如直接读位置索引,假阳性导致浪费IO。所以本文提出用两个bloom filter即after和before,(after是ES中原有的),比如短语查询:“United States“这样就可以选择查询”States“是否在”United“后 和 ”United“是否在”States“前和直接读取位置索引。
为了减小存储空间,WISER将过滤器分组如图3所示,每组用一个跳表来跳,每组用一个bitmap来标记空的过滤器,只存储非空的过滤器组,这样空过滤器的这个组就只用1比特来存储。维基百科数据有三分之一空过滤器,来自于词后面的标点和停用词等。所以双向的成本感知的bloom filter通过选择读取较少的数据来减少IO,并通过调整过滤器大小来提高精度。
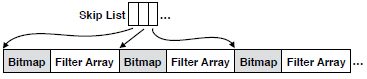
图3 WISER bloom filter
自适应预取
ES用linux系统的预取机制,每次预取固定大小的数据(128KB),当词的索引数据比较小时,造成读放大,所以WISER用词的偏移的前16bit记录预取区域的大小,并采用不定长度的预取如图4所示,预取区域包括docid和tf这些是最常用的数据。
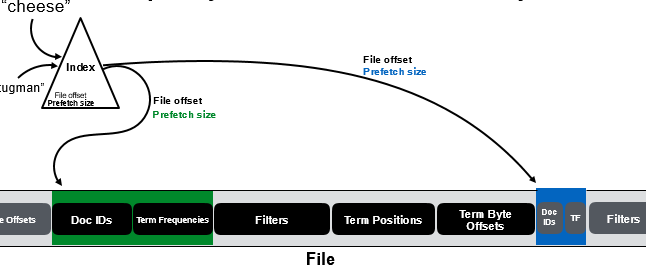
图4 WISER 自适应预取
文档压缩的时空权衡
ES为了提高压缩率将文档按组压缩,解压后面的文档就必须把前面也读出来并解压,本文是用空间换IO,每个文档一压缩并进行边界对齐以避免浪费IO和cpu。
效果测试
WISER在不同大小内存的性能如图5所示,Wiser_base是只有跨阶段数据分组的优化,a和b子图中可以看到与Elasticsearch相比,wiser的两个版本都具有更高的查询吞吐量和更低的查询延迟。 从c子图中可以看到WISER显著提高了带宽。d子图中,当内存大小较大时,Elasticsearch和WISER之间的流量大小是相似的,但是由于数据分组的原因,当我们减少内存大小时,WISER的流量大小的增长速度比Elasticsearch慢得多,d子图中wiser_final比wiser_base有更多的读流量,是因为wiser_final开了预取,一次I/O最小为4kb,在短链上有浪费。
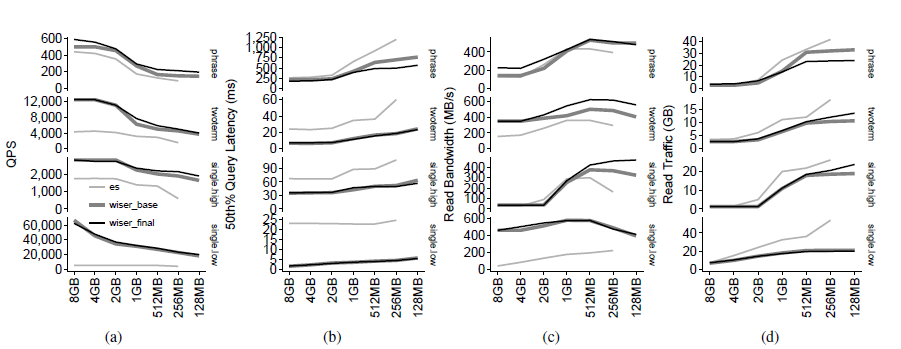
图 5 不同内存大小下WISER性能
自己的认识和体会(包括与自己工作的联系和启发等)
1、“按需存储”是一个理念,随着存储设备读取性能的不断提高,这个理念应该可以应用到更多的领域。
2、文中的一文档一压缩的方法增加了25%的存储空间,后期应该可以通过改变压缩方法来缩小空间。
·3、本文采用的SSD,如果用OPTANE会得到更大的效果提升。