
NBJL 2020论文导读28: A Deep Reinforcement Learning Framework forhitectural Exploration: A Routerless NoC Case Study
陈萱
论文(以及slide)下载地址:https://ieeexplore.ieee.org/abstract/document/9065600
论文信息: 论文发表在2020HPCA,作者是Ting-Ru Lin ; Drew Penney ; Massoud Pedram 等
论文摘要(包括论文动机、创新点或者贡献,论文的结论等)
在传统的基于路由器的片上网络中,路由器结构能够占据芯片11%的面积开销和最高28%的电源开销。无路由的片上网络,通过添加多个回路集合以保证各个结点之间的通信需要。为了高效的在状态空间中搜索回路集合,这篇论文将深度强化学习的框架应用于片上网络的设计中,使用蒙特卡洛搜索树在庞大的状态空间中进行搜索,并结合多线程学习技术以提高搜索效率。相比于之前最优的设计方案,该方法提高了3.25倍的吞吐量,数据包延迟减低了1.18倍,平均跳数减少了1.14倍,能耗开销减少了6.3%。
论文内容
论文中提出的深度强化学习框架如下图所示,智能体在当前的状态做出动作,获得一个动作评价作为反馈,根据反馈信号优化自己的策略,直到得到一个最优的策略。片上网络的状态使用跳数矩阵表示,N×N的网络中每个结点都有一个N×N的矩阵表示从该结点到达其他结点的跳数,所有结点的小矩阵形成了最终的N2×N2的跳数矩阵,以表示环境当前的状态。智能做出的动作使用五维元组表示添加的回路的对角顶点的坐标和回路中数据流动的方向。
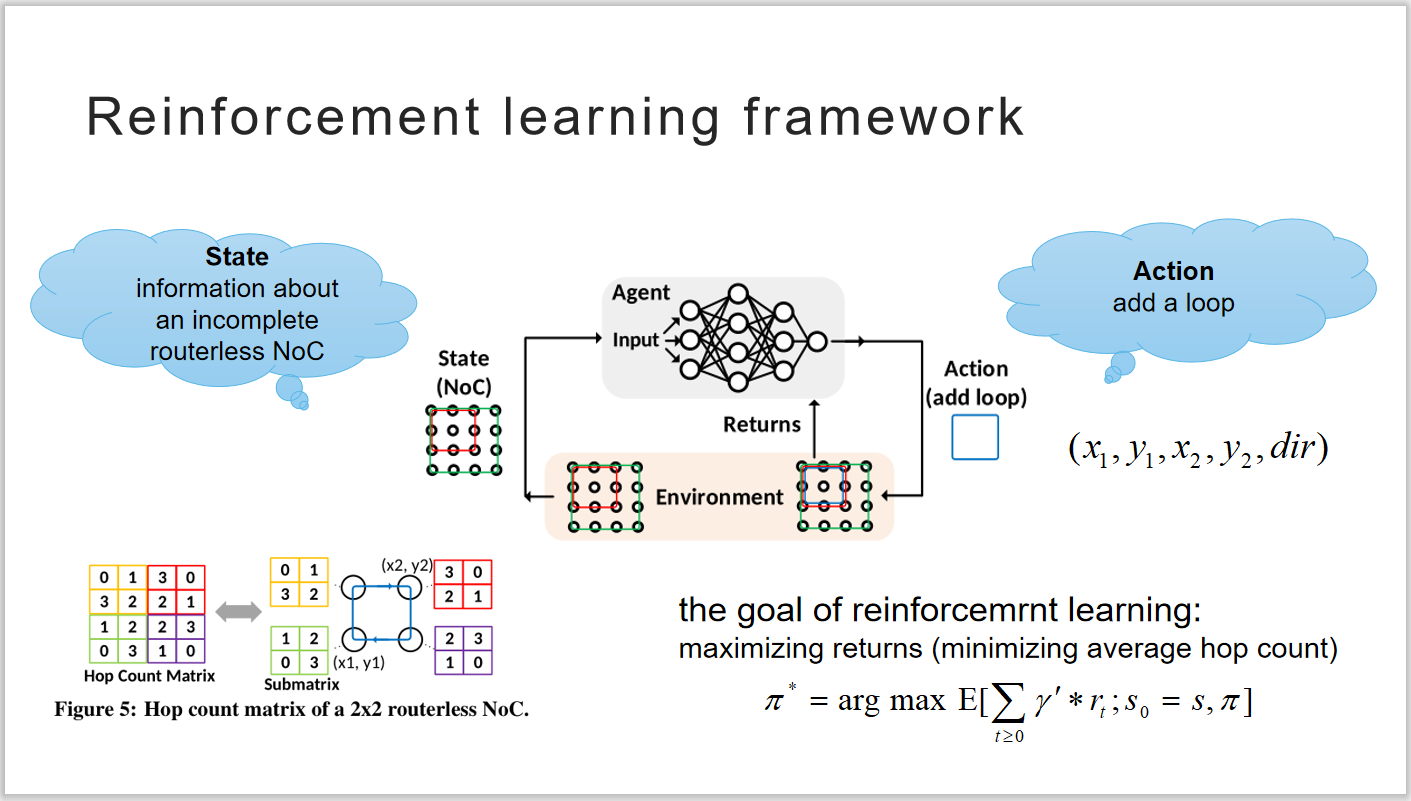
图 1 强化学习框架
本文中使用深度神经网络DNN作为智能体,DNN的输入是环境当前的状态,使用残差神经网络减缓网络过深所带来的梯度消失,使用卷积神经核对当前状态的空间分布提取特征,网络最终输出的是智能体根据当前状态做出的动作,以及对该动作的预测累计收益。
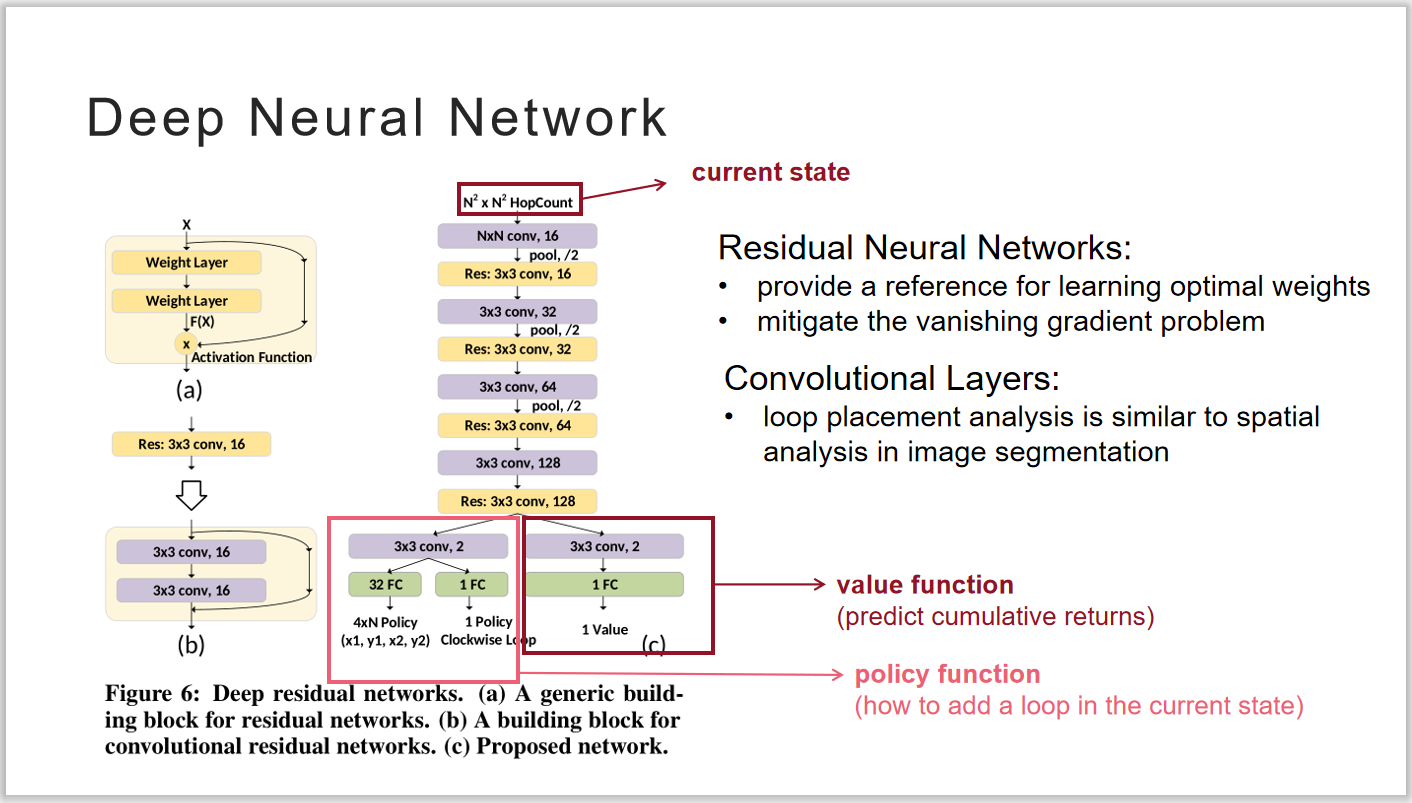
图 2DNN结构
为了对已经搜索过的状态进行保存,本文使用蒙特卡洛树搜索算法。使用确定的策略在已知的状态空间中进行搜索,找到最优的叶子结点。在叶子结点处使用DNN作出动作决策,向向未知的空间中进行拓展。寻找最优回路集合的过程,其实也就是建立一棵蒙特卡洛搜索树的过程。
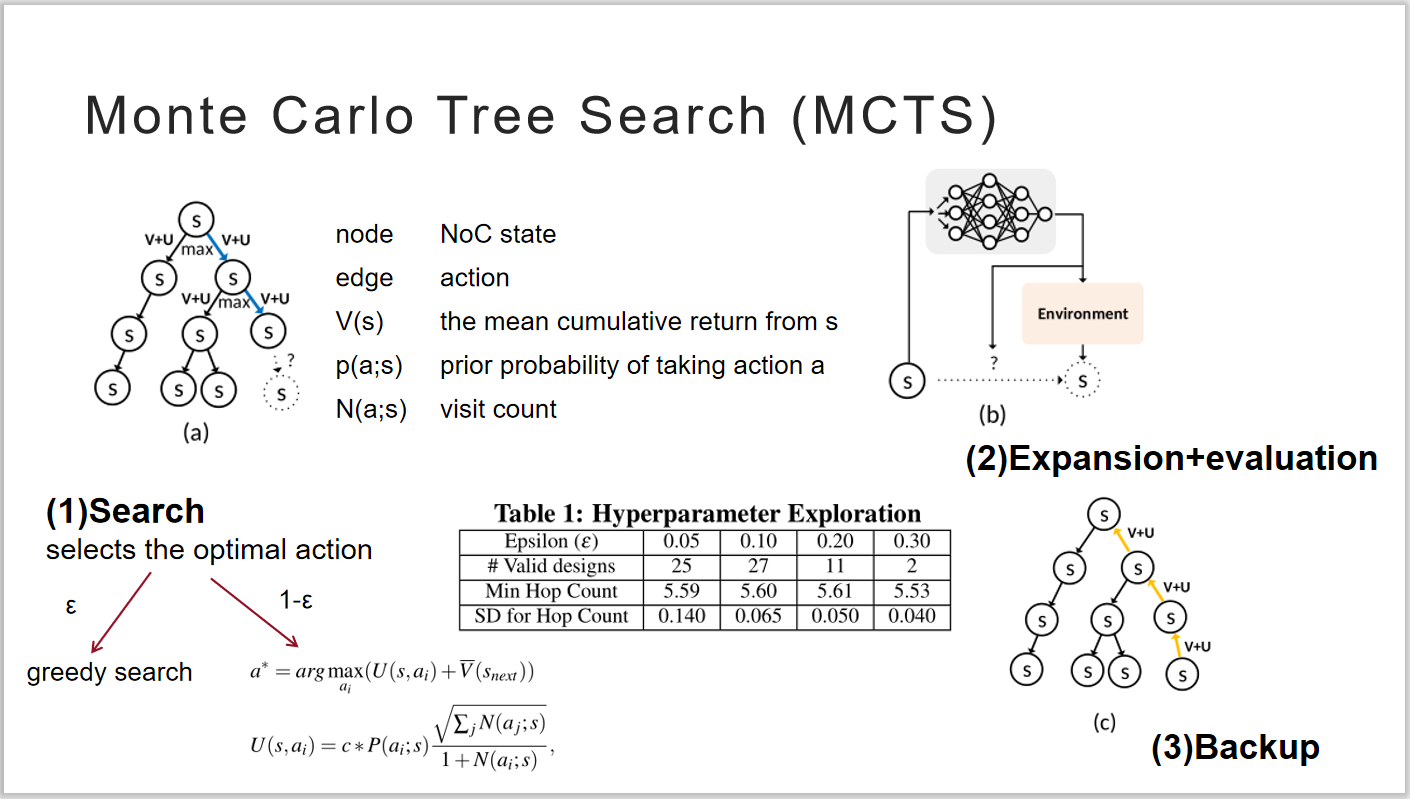
图 3 蒙特卡洛树搜索
为了进一步提高搜索效率,本文中还是用了多线程的学习技术。父线程产生n个子线程,并将全局参数分别送给每个线程。各个子线程均有自己的DNN,独立的进行训练,将学习得到的梯度发送给父线程。父线程在对梯度进行平均后,更新全局参数。论文中指出,对于规模大小为10×10的片上网络,10个小时的时间内,单线程只能获得6个有效设计,而多线程可以获得49个有效设计,大幅提高了搜索效率。
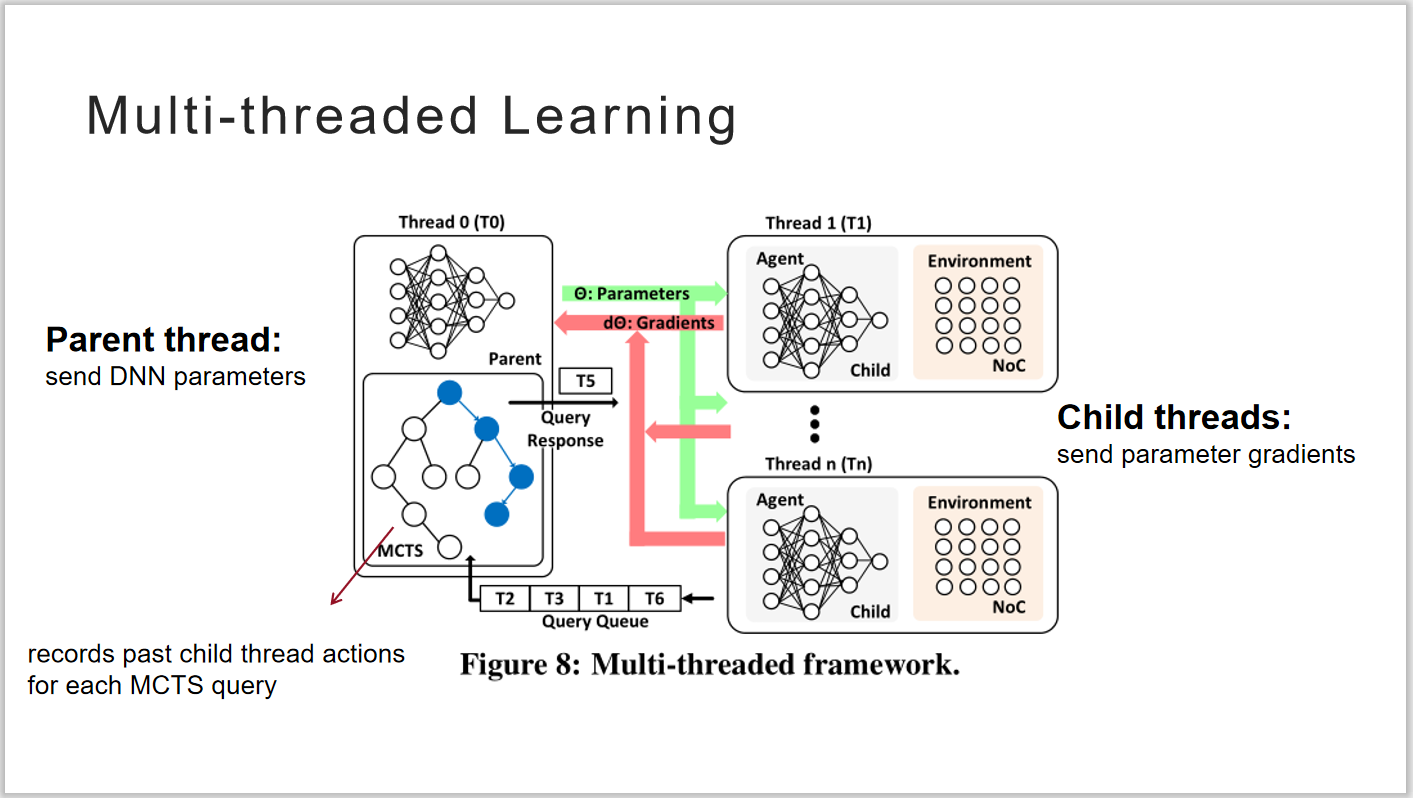
图 4 多线程学习
自己的认识和体会
这篇论文提出了一种结合了蒙特卡洛树搜索的深度强化学习框架,并将其应用于无路由的片上网络设计中,相比于之前最优的设计方法可以获得更多有效回路放置方案,同时也大幅提高了搜索效率。在实验部分可以看出,本文提出的方法相比于传统的Mesh结构在网络延迟和平均跳数等性能上均有了较大的提高,但是相比于之前最优的无路由设计方法,性能提升并不是特别显著。我认为原因主要在于该方法更侧重于如何获得尽可能多的设计方案,而没有在搜索过程中尽可能寻找较优的设计方案,未来考虑对该方法进行改进以提高搜索得到的设计方案的质量。