
NBJL 2020论文导读24:Making Disk Failure Predictions SMARTer!
刘冬实
论文(以及slide)下载地址:https://www.usenix.org/conference/fast20/presentation/lu
论文信息:论文发表于FAST`20,作者为韦恩州立大学的Sidi Lu、Bing Luo、Yongtao Yao、Weisong Shi和东北大学的Tirthak Patel、Devesh Tiwari。
论文摘要
硬盘是目前数据中心的主要存储介质,数据中心硬件替换和服务器故障的主要原因。硬盘故障可能会导致数据丢失、服务不可用,且在数据恢复时会造成资源浪费等经济损失。硬盘可靠性领域的研究对存储机构具有重要意义,但目前研究较少且受到样本规模的限制。
论文使用了一个来自大型商用数据中心的数据集,包括来自64个数据中心局点,10000个机架,采集时间超过2个月的380000块机械硬盘,目标是使用该数据集在较长的预测区间上准确预测硬盘故障。论文不只使用硬盘SMART特征,还首次使用了硬盘performance和location数据。
论文内容
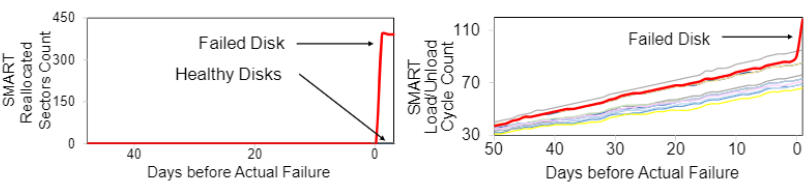
论文首先分析了SMART特征的局限性。如下图所示,SMART特征仅在故障发生前几个小时发生明显变化,无法在较长的提前预测时间窗口下达到较强的预测能力。
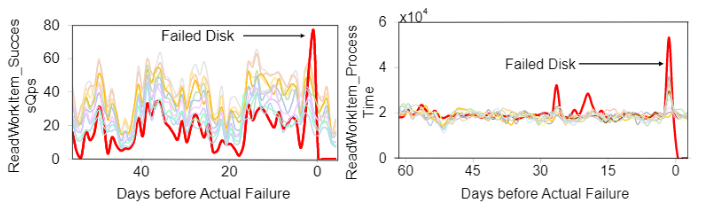
对于performance特征,相比SMART特征其变化更频繁,且在健康硬盘和故障硬盘将可以体现出差异,增加了SMART特征未覆盖的负载信息表现能力。
location特征包含局点、机房、机架、服务器四个维度,表示了硬盘在空间上的临近信息。空间上临近的硬盘在温度、湿度等环境因素以及震动等级上接近,这些条件均会影响硬盘可靠性。
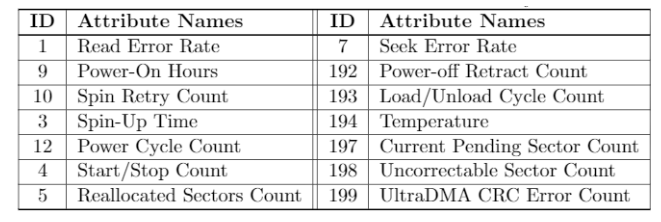
每个SMART特征包含raw值和normalized值,raw值由厂商制定,normalized值是由raw值归一化到1byte。SMART数据采集周期为1天,论文中使用的SMART属性如下图所示。
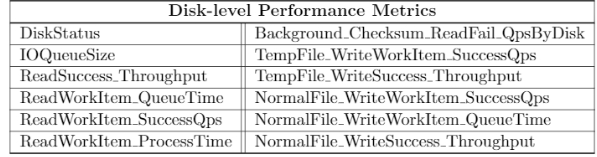
performance特征包括硬盘级别的指标和服务器级别的指标,采集周期为小时,具体指标如下面两图所示。
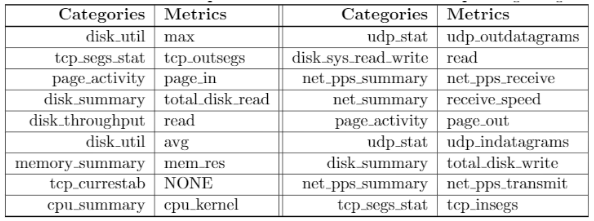
location指标包含局点、机房、机架、服务器四个维度,但不表示两块硬盘间的实际物理距离,四个维度具体个数如下图所示。

在特征选择前,首先使用min-max标准化方法对数据进行标准化处理,接着使用J-Index方法进行特征选择,J-Index分类公式如下:
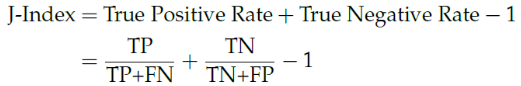
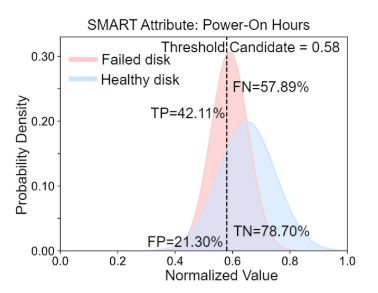
对于每个特征,根据0.01步长设定阈值,根据阈值计算J-Index值,选取J-Index值最高的分类阈值。通过比较J-Index值,进行特征选择工作。
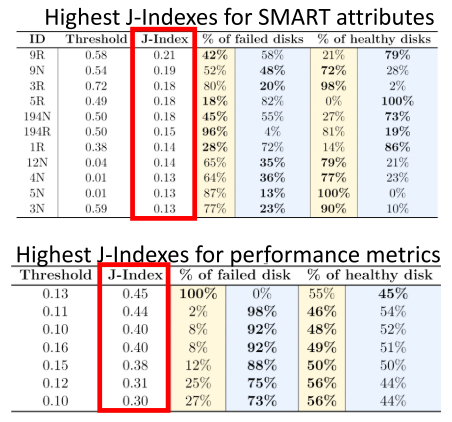
SMART和performance数据J-Index结果如下图所示。可以看到performance指标J-Index值普遍高于SMART特征,说明performance特征对硬盘故障更有区分作用。
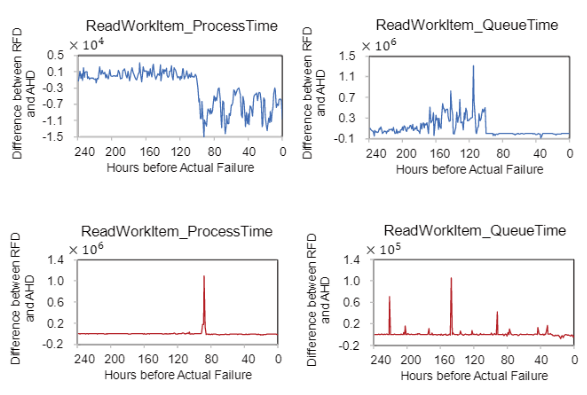
论文接下来对performance指标在同一服务器上健康硬盘和故障硬盘的差异进行分析。下图使用故障前240小时的数据,上面两个图表示一些故障硬盘开始时和健康硬盘表现一直,临近故障时表现开始变得不稳定。下面两个图表示一些故障硬盘在故障发生前会出现尖锐。
在评估模型性能时,使用的评价指标如下:

模型选择如下:

用S表示SMART特征,P表示performance特征,L表示location特征,论文使用了6组特征组合:

模型目标为预测硬盘在接下来的10天是否会发生故障,预测结果如下图所示:
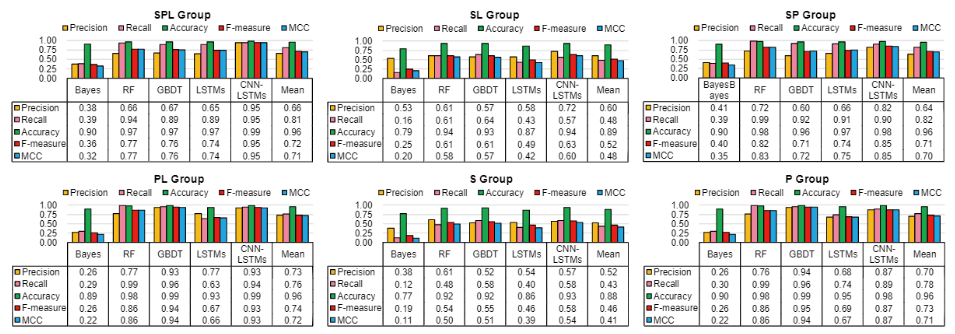
可以看到SPL特征组合在所有模型上取得了最优预测效果,说明performance和location特征的引入可以提升硬盘故障预测性能。同时location特征对模型性能的提升在performance特征同时出现时表现更加明显,location特征可以表示出performance特征的隐含模式。CNN-LSTM模型基本在所有情形中取得了最优性能。但当仅适用SMART特征时,RF和GBDT模型可以取得和神经网络模型近似的性能,这时选用RF和GBDT模型可以节省模型训练成本。
在对模型误报率和漏报率分析时发现,仅使用SMART特征时模型漏报率较高,而增加performance和location特征后模型误报率有明显下降,模型预测性能提升。

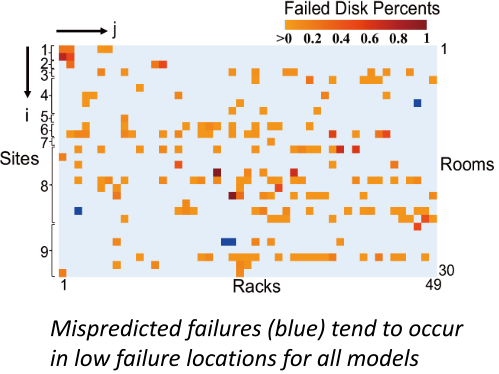
错误的故障预测结果多集中于故障硬盘样本分布较少的位置,因为机器学习模型无法收集到足够的数据用于训练模型,从而说明location数据的重要性。
在开始的时间区间,模型误报率较低,漏报率较高。即在数据不足时,模型倾向于将硬盘预测为健康硬盘,所以为保证模型预测效果,足够的测试区间是必要的。

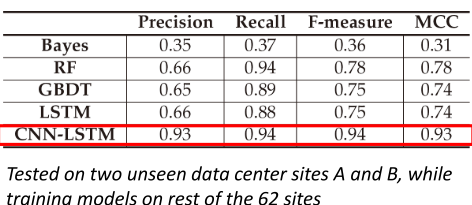
在测试模型跨数据中心性能时,当使用一个数据中心局点的数据训练模型,去预测另一个数据中心局点的数据时,模型效果很差。但当使用多个数据中心局点的数据训练模型,去预测未见过的数据中心局点数据时,可以取得较优性能,且CNN-LSTM模型表现最好。
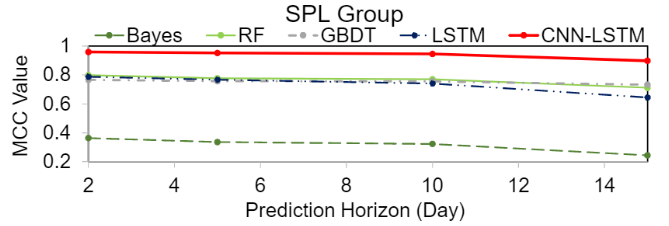
论文还评估了模型预测效果随着提前预测时间的变化,可以看到模型预测效果随着预测时间的增加会逐渐下降,但下降不是很陡峭。
论文最后评估了使用J-Index方法进行特征选择的效果,与使用全部特征的结果进行对比。可以看到特征选择后模型效果与使用全部特征效果接近,且使用特征选择后特征可以节省大量存储空间。
自己的认识和体会
performance和location数据可以提升硬盘故障预测的性能,后续工作中可以考虑加入以上特征。在使用lstm模型前,加入cnn网络对特征进行提取,可以提升lstm模型的预测性能。