
NBJL 2020论文导读23:A High Throughput B+tree for SIMD architectures
高钰洋
本文发表于TPDS 2019,提出了一种使用SIMD加速B+的技术。
SIMD技术在被广泛的应用于对算法和应用的加速中,但是不是所有的算法和应用都与SIMD有很好的契合。B+树结构与SIMD之间存在一些
契合的地方,这导致了原本的B+树结构直接应用于SIMD架构不能获得很好的加速效果。
作者进行了一定的实验测试,分析B+树结构与SIMD架构之间的gaps。首先是方寸的gap:由于搜索需要从B+树的根节点遍历到叶节点。对于阶数较大的B+树,对cache的利用率较差,会造成较多的cache miss。且由于query生成的随机性。同一个SIMD单元负责的查询们可能会走向不同的分支。这就无法利用合并访存来减少对全局内存的访问。其次。对于不同的查询来说,比较次数是不同的,这也会带来计算资源的浪费。
结构
所以本文提出了一种新的B+树的结构Harmonia。将传统的B+树结构(图1a)改为了图1(b)所示的两个一维数组的结构。
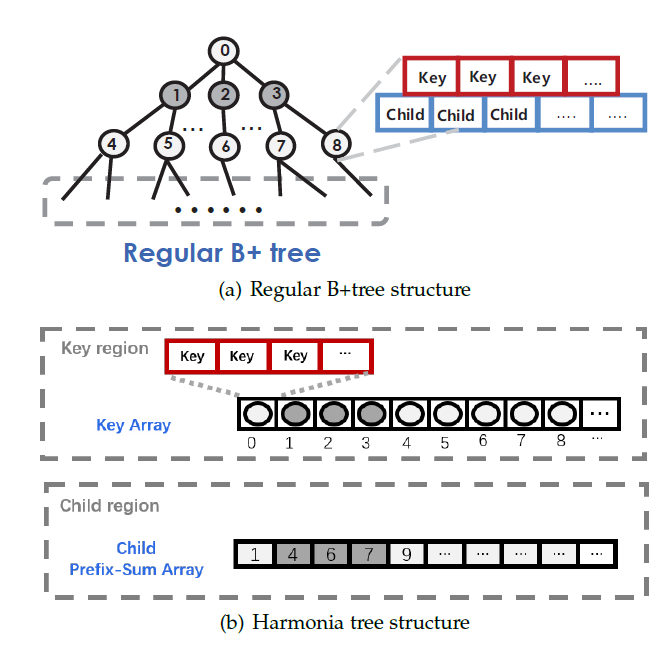
图1
其中key区域以广度优先的顺序存储了所有结点的key值。Key数组中每个结点的大小固定位(fanout-1)*keysize。Chile区域存储每个结点的第一个孩子结点在key数组中的索引。这样可以通过child数组快速找到目标结点在key数组中的索引。
B+树操作
对于此树结构,搜索和范围搜索都是较为简单的。通过key数组和child数组方便的找到目标结点的索引。对于更新和插入删除操作来说。更新操作跟查询操作类似,找到目标结点,更改其value值即可。对于插入和删除操作来说,以插入操作为例。当我们插入一个数时,会出现两种情况:1.插入的结点未满,不会造成节点的分裂,直接插入并更新相应的结点和child数组即可。2.插入结点已满,需要进行分裂,由于key是按照广度优先策略存储的,新增节点需要将后续的结点向后移动,由于元素的移动带来很多开销,论文中使用了批处理的方法,用辅助结点来存储当前分裂的结点。最后将多个更新一起进行元素的移动,来减小元素移动带来的开销。当然分裂和合并节点的操作需要满足线程安全的特征,论文中用了粗细粒度锁来提高并行性,这里不再详细介绍,可以参考论文中的描述。
优化方案
论文中提出了两种优化方案来提高性能。第一种是Partially-Sorted Aggregation (PSA) ,即对查询进行部分排序。由于我们希望最大程度的利用合并访存来减少访存次数。我们希望同一个SIMD单元负责的查询尽量接近,如图2所示。简单的想法是对查询进行排序,但是全部排序会带来大量的消耗,甚至会导致总时间比之前还要长。
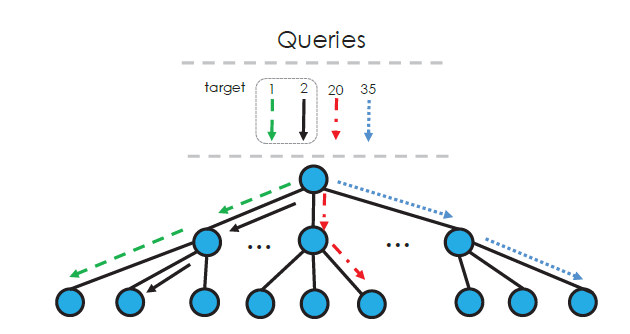
图2
但是看图会发现,第一个SIMD单元处理1,2查询和2,1查询是等价的,这就启示我们不需要对查询进行完全的排序,只需要对其进行部分排序即可。对于基数排序来说,我们只需要排序其最高的N位即可。那这个N值该取多少呢。文中使用下述公式进行了计算,假设Key的位数是B,树的大小是B,每个cache line可以装K个key值,则
即我们只需要排序对查询的前k位进行排序即可达到较好的效果,实验也证明了排序前N位可以达到与全部排序相当的查询性能。
第二种优化为Narrowed thread-group traversal (NTG),即减少每个执行每个查询的线程数目。很多工作都是启动与fanout数目相同的线程,但是对于每个节点的比较,有80%的可能性会落在前50%,这就会带来很多无用的比较,浪费计算资源。但是每个SIMD单元执行多个query会带来分支发散的问题。这就需要我们找到一个合适的每个SIMD执行的query的数目。TP表示吞吐,由于执行时间T与比较的轮数S成正比,我们是用S代替执行时间T,GS表示执行一个query的线程数。所以
这个比值公式可以比较两种不同的策略之间的吞吐比,其中由于我们测试时每次GS值都缩小到1/2,所以G可以看做常数,所以这个比值的大小取决于不同策略之间的比较轮次的比值。进行试验,每次将执行一个query的线程数缩小到1/2,如果该比值大于1,则继续缩小,直到小于1为止,以此获得最好的NTGsize。
实验
本文在CPU和GPU端都实现了本文的Harmonia结构,CPU端使用OpenMP,GPU端使用CUDA,GPU实现中搜索在GPU进行,更新在CPU端进行。结果与HB+tree进行比较。
本文进行了大量且详细的试验,实验结果能很好地支撑本文的论点,实验的完备我觉得也是本文的优点之一,这里不一一列出试验,只列出优化方法对性能影响的实验结果,想看完整实验结果的可以参考论文原文。
作者测试了两种优化方法对性能的影响,如图3(GPU端)和图4(CPU端)所示

图3
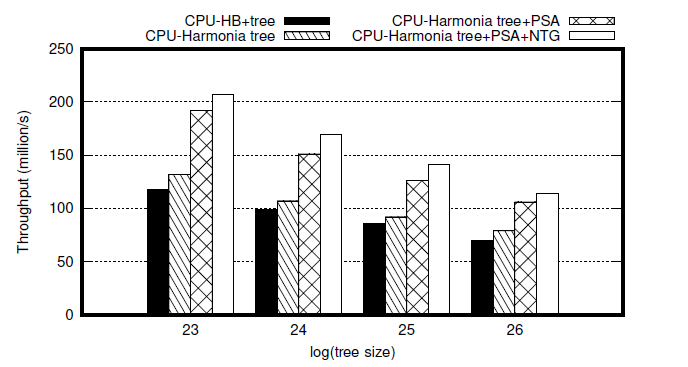
图4
可以看出,两种优化方法尤其是NTG可以带来很好的性能提升,尤其是在GPU性能提升较大,这是由于GPU端一个SIMD端的线程数较多,资源浪费现象比较严重。