
NBJL 2020论文导读22:PARTIES: QoS-Aware Resource Partitioning for Multiple Interactive Services
段剀越
论文(以及slide)下载地址:https://sc2682cornell.github.io/publication/parties/
· 论文信息: 论文发表于 2019年4月,在ASPLOS‘19上,作者为
Shuang Chen、Christina Delimitrou 和José F. Martínez,于康奈尔大学。
一、论文摘要(包括论文动机、创新点或者贡献,论文的结论等)
l 动机
1. 云应用逐渐从批处理转变成低延迟的服务。比如传统的以吞吐率为主的图像处理和大数据的应用在采用Spark和X-Stream框架后进入内存计算的阶段,这让任务执行延迟变为几毫秒或秒。
2. 云应用正在经历重大的重新设计——从单体式服务Monolith(它封装了完整的功能到单个二进制中)转变为成百上千个松耦合的微服务。仅管一个大规模的端到端的服务的延迟依旧保持在几毫秒或秒的粒度,每个微服务也必须满足更加严格的延迟约束,通常是几百微秒的级别。
3. 每个微服务处于一个小的且基本是无状态的容器中,这意味着许多容器需要被调度到一台物理机上以最大化利用率。当前的技术(每台物理机上只允许有一个高优先级的延迟敏感(LC)的服务与几个低优先级的批处理任务)无法满足新的场景
l 创新点
1. 验证“资源置换性(fungibility)”这个概念
2. 提出PARTIES(对多个交互式服务的划分),它是第一个针对多个延迟敏感(LC)应用的QoS有感资源管理器,它不需要应用的先验知识,通过动态监测,利用系统/硬件层面可划分9个共享资源。此外,PARTIES适用于动态变化的负载,并利用用资源替换性来快速实现收敛
l 结论
1. 提出了PARTIES,一个在线的资源控制器,它能够让多个延迟敏感的应用来在不违反QoS前提下共享一个物理主机。
2. PARTIES既利用硬件也利用软件隔离机制以保护QoS,并假设没有任何应用的QoS。
3. 对比评估了PARTIES和前沿的机制,展示出PARTIES实现了可观的高吞吐量,并在面对波动负载的同时满足QOS,并且它的收益随着混布应用的数目而增加。
二、论文内容
l 文章的脉络:作者先对六个应用进行特征化,从三个初步实验中观察到用在不同的资源划分下可以达到相同的QoS指标这一现象,提出了“资源置换性”这个概念;随后,作者提出了多LC应用的资源管理器PARTIES,叙述了它的三个方法Upsize(),Downsize()和migration和触发条件等细节;接着,作者进行了一系列实验,涉及对PARTIES有效性的验证、与前沿资源管理器的对比、开销,实验部分涉及不同数目的应用混布以及不同类型的负载(常量型、波动型);最终,作者得出结论,认为PARTIES能在满足应用的QoS前提下大幅提升吞吐率。
l 资源置换性
作者先进行了三个实验,特征化6个热门的开源LC服务,然后提出资源置换性:1.Memcached:高性能内存对象cache系统;2.Xapian:一个web搜索引擎包含在Tailbench suite中;3.NGINX:一个高性能HTTP服务器,当前负责41%的直播网站;4.Moses:一个基于统计的机器翻译系统(SMT),按照Tailbench配置;5.MongoDB:它是最热门的NoSQL数据库系统之一;6.Sphinx:一款语音识别系统配有声学、语音和语言模型。实验方法是从低的每秒请求率(RPS)开始,逐渐注入较高的请求率,直到服务器端对应用的请求开始掉落。分析应用在处理负载与延迟、干扰性、隔离的表现。
实验平台
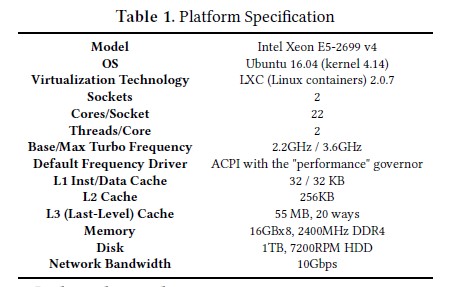
1. 第一个实验测试了应用在满足QoS的前提下最大可应对的负载(RPS)。
实验配置:1.每个应用初始化在各自的容器中。2.所有应用在超过一个负载阈值后经历了尾延迟的激增,通常是在它们最大RPS的60%-80%之间。3.每个应用的QoS目标是拐点的第99个百分位的延迟,此时每个拐点的RPS定义为max load,它是机器在满足QoS的同时可维持的吞吐率的最大值。
观察:QoS目标从几微秒到几秒不等,它们有不同数目的用户空间、内核空间、I/O处理;它们的指令与数据足迹变化很大;他们的内存、磁盘、网络带宽请求也变化很大。
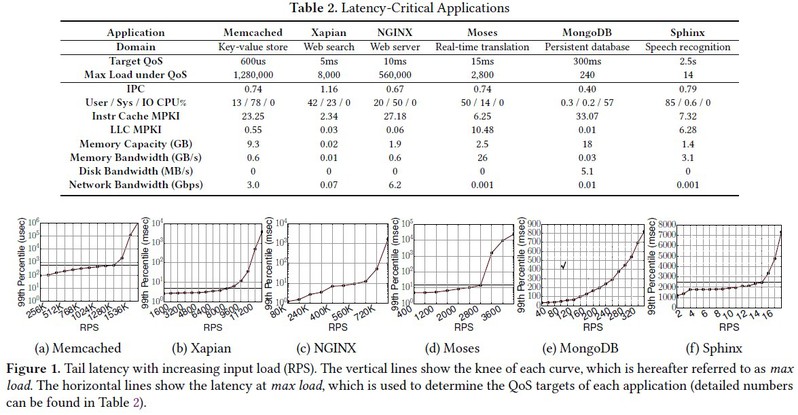
2.第二个实验是关于应用在microbenchmark的干扰下,在满足QoS的同时能达成的最大负载(向max load对齐),这个实验探究不同资源对应用达成QoS的影响;
实验设置:1.客户端运行在三台志强服务器上,负责生成负载,用与主服务器有10Gbps连接2.这三台服务器上的客户端尽可能装满,使得客户端测得的延迟大体上是由服务器端的delay产生。3.每次实验客户端运行1分钟,每个负载生成器采用指数级的内部到达时间分布来模拟泊松过程;每个实验运行五次。4.独立发送与连续发生的请求有一个比例。请求的热度服从Zipfian分布(齐夫定律)。5.每个LC负载与microbenchmark混布(争夺系统不同资源),每个应用初始化为有8个线程,它们被绑定pin到8个不同物理核上的8个超线程上。6.干扰机制:hyperthread——将8个计算密集型BENC混布到与LC相同的超线程上;CPU——同hyperthread,但不同物理核;LLC/内存的 带宽/容量——cache/memory thrashing BENC,用于产生流量/占用空间;power——12个计算密集型BENC(power viruses)映射到6个空闲CPU的12个逻辑核上。

观察:1.通常应用对他们资源利用率饱和的资源最敏感。比如Moses和Sphinx对cache容量与内存带宽有较高需求。(它们有较高的LLC MPKI和内存带宽)。对于这些应用,在此类资源上的干扰会导致QoS违规。2.资源的高利用率并不总是与相同资源的干扰的敏感度相关。比如,Memcached对内存带宽干扰高度敏感,但它不使用大量的带宽。这是由于它严苛的QoS目标:Memcached的请求必须在几百微秒内完成。3.除MongoDB外所有应用,共享超线程导致高延迟。在不同的超线程上共享物理核心也会导致吞吐率显著下降。因为混布在相同物理核心导致L1、L2的争夺,软硬件的隔离都无法缓解,故不允许共享物理核。
3. 第三个实验关于应用在高低负载下,对不同的资源进行划分(使用软硬件的隔离机制)来判断这样的划分可否达成应用的QoS。先测试计算型资源再是存储型资源。
实验配置:1.隔离机制:对核心的隔离——采用Linux的cpuset cgroups,用它将指定的核心id绑定到指定的应用;对功率的隔离——有“用户空间”管理卡的ACPI频率驱动器为宣宗的核心设置固定的频率(1.2-2.2GHz,增量为100MHz),或用“性能”管理卡运行在睿频中;LLC隔离——Intel的Cache分配技术(CAT)用来划分LLC way,它也间接地调整了内存带宽因为内存流量与cache命中率高度相关,在评测的服务器平台下没有直接划分内存带宽的机制;内存隔离——采用Linux的 memorycgroups来限制每个容器最大的内存使用量;磁盘隔离——采用Linux的blkio cgroups来限制每个容器的磁盘读带宽的最大值;网络隔离——采用Linux的有层级令牌桶(HTB)的qdisc流量控制调度器来限制上传带宽。2. 实验步骤:先单独运行每个应用(下图a,b),使用隔离机制来确定可分配的资源的上限;随后将每个应用与thrash空闲核心上内存带宽的micro-BENC混布(下图c)以研究什么范围的隔离机制可以消除干扰。网络带宽与其他资源不同,它表现地像个阈值,只要它足够QoS就能满足。
计算型资源
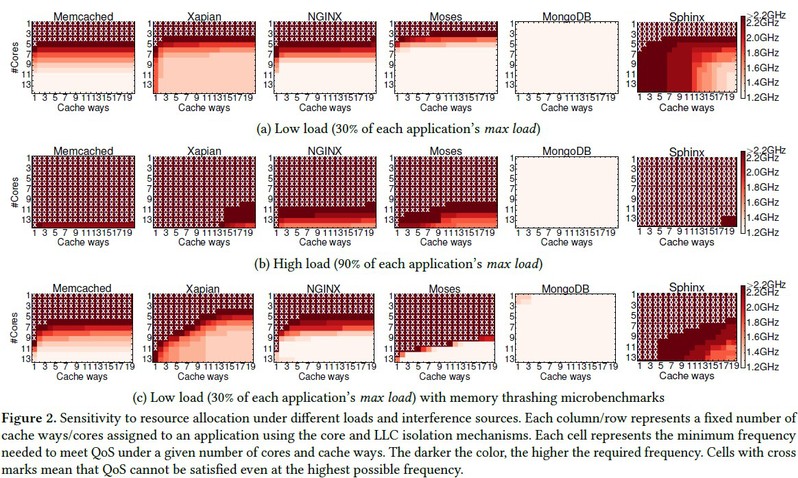
观察:对于图(a,b): (1) 所有应用除MongoDB对核心分配最为敏感,当核心不足时会违反QoS; (2)当核心充足时,频率和cache路都可以降低,并同时满足QoS; (3)MongoDB受I/O流量主导,仅用单个核心在其最低频率下便能满足高负载下的QoS; (3)大部分应用对LLC分配不是高度敏感尤其是在低负载的时候,这是因为云服务在开始的时候的大数据集不适用于LLC; (4)一些应用在高负载时对cache的需求依旧增加,如Xapian,这是因为当前请求的数据被重用; 对于图(c): (1) 发现LLC需求增加,这使得划分变得很重要; (2)对核心及频率的需求也增加,这是因为需要更快的计算来掩盖由增长的cache misses造成的高的访存延迟。
存储型资源
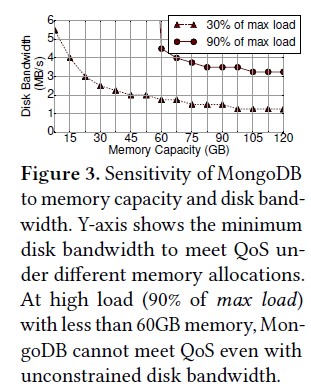
观察:1.大部分所研究的应用不涉及磁盘操作,增加他们的内存容量的分配至超过他们各自的数据集规模并不能改善性能。但MongoDB是I/O密集型应用,它用内存作为一个软件cache来缓解到持久存储的流量。 2.随着内存容量增加,更多的请求命中内存,MongoDB在低磁盘带宽下达到了相同的延迟。
4. 资源置换性
PARTIES的关键是——资源替换性,即资源可以彼此替换。这有利于减少找出一个满足QoS分配所需的时间:其一,对给定的应用与负载,资源上更多的灵活度能满足所有协同调度的应用的QoS其二,探索可能分配的所用的启发式可以保持相对简单的特性,因为找到一种令人满意的分配足矣
事实上,对给定的应用任意跟定的负载,会有多个可行的资源元组。依据图2-b,Moses在高负载下,<10 cores, 11 cache ways, turbo feq>,<14 cores, 11 cache ways, 1.8 GHz>, <14 cores, 2 cache ways, 2.2 GHz>这三个配置都可满足QoS。
l PARTIES
1. 概述与原则
概述:PARTIES是基于反馈的控制器,它利用细粒度的检测与资源划分动态地调整混布的LC应用间的资源分配,以满足所有应用的QoS为目标。
设计四原则:
i. 资源的分配决策是动态的且是细粒度的。LC应用对资源分配很敏感,次优的决策即便很少也能导致QoS违规。细粒度的检测可侦测出这源需求的激增,并阻止这些激增的发生。
ii. 不需要应用的先验知识或/和它的描述。对所有可能的应用混布中创建离线的描述,即便可行的其代价也会极其高昂。此外,获得此项信息也不总是可行的,尤其在公有云环境中。相反地,资源置换性使PARTIES能够在线地找出可行的分配,而不依赖经验为每个应用调参。
iii. 控制器从错误的决策中快速地恢复。因为PARTIES在线地探索了分配的空间,它的一些决策可能会适得其反。通过利用细粒度的在线检测,PARTIES可以快速地侦测出这些事件并恢复。
iv. 万不得已时才迁移。当混布应用的资源需求总额超过了机器的总容量,就无法满足所有服务的QoS,负载迁移就是唯一的补救措施。由于迁移的高昂开销,PARTIES会选择那些性能受迁移影响最小的应用去做,因为这个应用要么是无状态的,要么有一个松散的QoS目标。
2. PARTIES控制器(概述和主要的操作)
概述:PARTIES由一个检测组件和一个资源分配组件组成。前者检测每个应用的尾延迟、内存容量、网络带宽使用量,后者使用检测结果来决定恰当的资源分配,并强制对他们隔离。
主要操作:控制器从公平的分配开始,即每个应用收到相等的划分,且所有处理器运行在标称频率上。初始化后,尾延迟及资源利用率每500毫秒采样一次,并基于测量值和每个应用的尾延迟的松弛度( slack[A]←(target[A]-latency[A])/target[A],其中A是一个应用,target表示它的QoS目标)来调整资源,有三个主要操作:
i. 如果至少有一个应用几乎没有或有负的松弛度,即QoS被违反或将被违反,PARTIES从有最小松弛度的应用S开始,分派更多的资源给这个应用; 记为upsize()。
ii. 当所有应用轻易地满足了他们的QoS,PARTIES将减少有最高尾延迟松弛度的应用L所分到的资源。回收过量的资源可降低功耗,或者空出资源给混布的job,这提升了机器效能; 记为downsize()。
iii. 另有一个计时器以记录QoS违反持续了多久:若满足QoS,计时器被重置;若在1分钟内无法找出满足所有应用QoS的分配,迁移会被触发以降低服务器负载并阻止性能衰减。
迁移过程会涉及:(1)选择一个待迁移的应用;(2)在一个低负载的机器上创建该应用的实例;(3)将请求从当前实例重定向到新的实例;(4)终止之前的实例。PARTIES会选择迁移一个产生最少迁移开销的应用:无状态的服务(比有状态的)不需要迁移内存中的数据,这引入了较低的迁移开销;当所有混布任务是有状态的,选择迁移有最松散QOS目标的。
Upsize和Downsize的触发条件:前者slack[S]<0.05;后者slack[L]>0.2.
3. Upsize 与 Downsize分配
Upsize()和Downsize()函数将资源从一个应用迁移到另一个应用。为此,它们首先选择一个待调整的资源,接着通过监测延迟与利用率来评估调整的影响:
i. 在Upsize()中,如果延迟降低了,那么调整就是有益的;在downsize()中,只要调整后的QoS依旧满足则这次调整是可接受的。。
ii. .Upsize对于无益的操作定义:采取分配后 new_latency > old_latency,则换到下一个资源去调整
iii. Downsize对于不可接受的操作定义:回收分配后就new_slack<0.05,则回滚刚才的回收操作,换到下一个资源去调整
iv. 若调整无益处,控制器切换到不同资源——对于Downsize(),措施会被立即复原以恢复错误的决策,且该应用会被禁止downsize()达30秒;对于Upsize(),则不执行回滚以防缺少多维资源。只要满足QoS,过量资源随后会被回收
v. 如果在Upsize计算资源后:若内存松弛度很大且延迟没有下降,这很可能是分配的计算资源不足;如果内存几乎饱和,QoS违规很可能是一个变大的数据集造成,这是控制器会跳转到存储轮
vi. 当Upsize应用A时, 控制器寻找另一个应用B来从它上面回收资源:如果混布的job存在,PARTIES优先从这些任务上回收资源; 否则会选择有最高尾延迟松弛度的LC应用(L视为B)。而Downsized挤出的资源给混布的job(若存在)或保持空闲。
vii 资源调整的单位是细粒度的,如1个核心、1行cache way、100 MHz、1 GB内存、1GB/s 磁盘带宽。Upsize回收的资源不能和扩充的资源相同。(ping-pong)
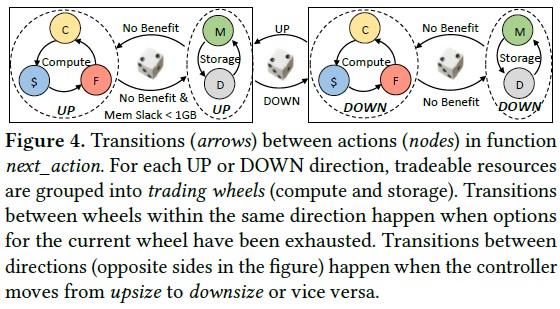
如图4所示,分配决策由<direction, resource>决定,即<UP/DOWN, CORE/CACHE/FREQ/MEM/DISK>。初始随机选择资源去调整,且决策在亚秒内产生。对于一个应用A,如果对它执行Upsize,随机选择一个资源,如存储型资源内存MEM,可能有如下过程:<UP,MEM>--<UP,DISK>--<UP,CORE>--<UP,FREQ>。注意,这里从存储型资源切换到了计算型资源(注:因为PARTIES发现调整存储型资源都试过了)。
4. 部分细节讨论
i. PARTIES需要知道关于应用的什么信息?
不需要除QoS目标外任何离线描述。但为了减少内存不足引发的错误,需要在线测定应用开始时1秒内的磁盘带宽使用量以区分一个应用是否为in-memory. 当它不涉及I\O时被认为是in-memory。
ii. 延迟如何监测?
在私有云中,内部应用已经仪表化来汇报他们的性能;在公有云上,应用要么汇报它们自己的性能,要么允许云服务提供商值入探测点来测量性能。
iii. 控制器参数如何确定?
1) 决策区间默认是500ms:更短的区间可以更快地侦测出潜在的QoS违规,但过多的调查导致噪声和不稳定的结果;更长的区间提供更好的稳定性,但延迟收敛。
2) Upsize中延迟松弛度被设为5%:较大的值可找出更多潜在的QoS违规,但是容易出现误报,这有损资源效率;Downsize中则被设为20%:较小的值会导致激进的资源回收,损害性能,但较高的值会降低资源利用率。
3) 依最差案例,触发迁移计时为1分钟。缩短它会有不必要的迁移,延长它会让QoS违规长期存在。
4) 更粗粒度的资源调整可能导致过于激进的资源回收和QoS违规,而更细粒度的调整会延长收敛
l 实验
1. 方法与Parties有效性(1)
配置
i. PARTIES是每个节点上的管理器;只有在迁移时会用一个全局可见的中央协调器以决定目的机器。
ii. 除了LC应用,还有一个多线程任务运行在单独的容器中,它由计算密集型的14个线程与内存thrashing的14个micro-BENC组成。它的吞吐率被定义为多个微基准测试的合计吞吐率。
方法:
先评估常量负载,稍后测试昼行性负载。负载为各自的max load的10%~100%。每次允许30秒的预热与60秒的测试,重复三次。若所有应用在1分钟后无法满足QoS,则此配置无法达到QoS
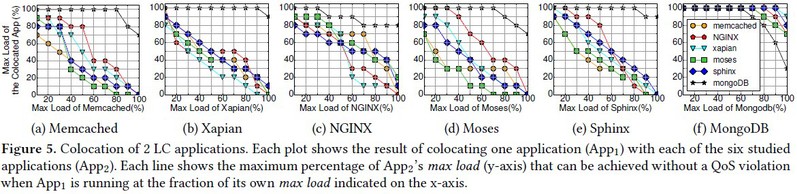
观察:1.一个应用可以运行在不违反QoS的情形下运行高负载,只要混布的应用运行在它们max load适当大小的负载上(通常是40%-60%)。2.MongoDB极容易接受混布运行的应用因为它的低计算需求,MongoDB与它混布的应用接近了各自的最大负载。唯一的例外是两个实例都是MongoDB,合计的吞吐率不超过160%,这是因为I\O的竞争
2. Parties有效性(2)
PARTIES被设计成支持任意数量的LC应用,下图(a)和(b)分别展示了3个应用与6应用混合的结果,其中前者为即Memcached和Xapian与其他三个应用混合,它们有所有最严格的QoS。
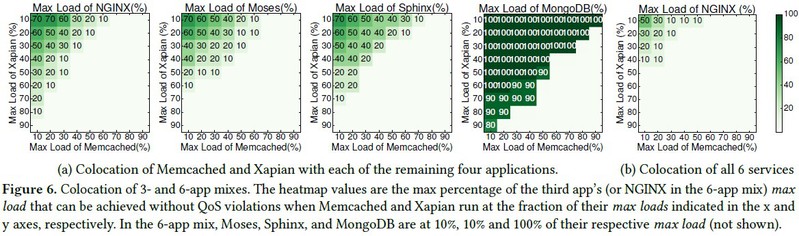
观察:PARTIES满足所有混布应用的QOS,直到机器被超购。如前,MongoDB受I/O影响的现象能节约出更多的资源给其他服务。
2. 对照算法一(Heracles)
与Heracles比较:它是用于为LC应用进行资源分配,不同于PARTIES,它被设计为为单个LC作业与一个或多个低优先级的混布的job运行。因此,当用多个LC服务测试Heracles时,我们选择有最严格的QoS的应用为LC应用,并将其他应用视为混布的job。在Heracles中混布的job之间没有划分。
评价指标:使用有效的机器利用率(EMU),EMU是被定义为所有混布的应用的合计负载最大值,其中每个应用的负载为它的max load的百分比。EMU可超过1,因为共享资源能更好地装箱
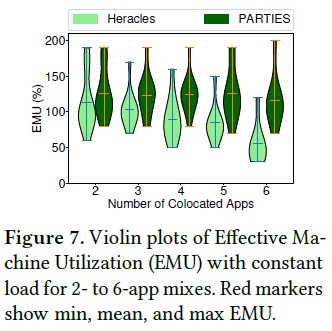
观察:PARTIES在2应用混合上比Heracles平均高13%。差距会随着混布应用的增加而扩大。在6应用场景下PARTIES比Heracles平均高61%。
分析
i. Heracles侦测到QoS违规就推迟混布job,若混布的job也是LC时就会适得其反;而PARTIES则会调整多个资源的划分来满足所有混布LC应用的QoS。
ii. Heracles在混布job之间没有资源划分,当有3+混布应用时会出问题,即产生较低的EMU,当混布的服务增加时Heracles与PARTIES之间的差距增大。
iii. Heracles可以同时使用多个资源控制器,但这在Downsize时过于激进,在Upsize时太保守,且它不用资源置换性;而Parties每次只调整一个资源。
iv. Heracles不支持内存空间或磁盘带宽划分,这在多I\O-bound的负载上明显。
4. 对照算法二(Unmanaged、Oracle)
Unmanaged:不使用隔离机制,ACPI频率驱动被设为默认的“ondemand”。Unmanaged的环境依赖于系统以调度应用与管理资源。Oracle:一个理想的管理器,它通过详尽的离线描述实现一个资源分配

n 观察:
i. Unmanaged最差,因它不直接管理干扰;
ii. 当Memcached与Xapian有相同的负载时,PARTIES的NGINX比Heracles 的高10%-30%,这增加了成本效益;
iii. PARTIES与Oracle表现相似,PARTIES的EMU最多比Oracle低10%;原因一,PARTIES总是以最小延迟松弛度来划分资源,这会导致应用之间的ping-pong;原因二,PARTIES的任何资源调整将花500+ms生效,这会导致资源过度分配。
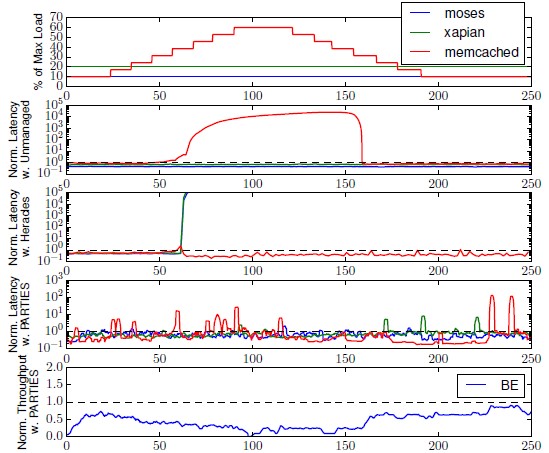
5. 波动负载
配置
昼行性模式中负载在白天会很高,在晚上会逐渐下降。此实验选择3个应用Memcached、Xapian和Moses的混布。前两个有最严格的QoS,最后一个对内存带宽压力最大。Memcached的负载变化为10%~60%,Moses和Xapian 的负载设为它们各自max load的10%和20%。实验结果见图9
观察:
i. 开始时系统是轻负载,PARTIES侦测到所有服务有较大的尾延迟松弛度,因而减少它们的核心和Cache,故混布的job因此得到更多的资源且有更高的吞吐率。
ii. 在25s,Memcached的负载从10%逐步增到60%。
iii. 在60s,Unmanaged的延迟急剧增长;Heracles侦测到QoS违规并暂停其他应用5分钟;PARTIES侦测到峰值,并把更多的资源分给Memcached,混布的job吞吐率由于可用资源变少而下降。
iv. 在约95s,Memcached和Xapian都开始经历QoS违规。PARTIES会Upsize他们的资源。结果是PARTIES在20秒内找出一个有效的分配,预防了进一步的QoS违规。
v. 在约120秒时,即使Memcached的负载开始下降,资源也没有被立即回收,因为延迟松弛度还很小。
vi. 在135秒时,PARTIES在应用的延迟松弛度大于0.2时Downsize一个应用;
vii. 随后,随着应用负载降低,混布的job的吞吐率增加。即使在这段时间内还有偶发的QoS的违规,延迟也能很快恢复,因为错误的Downsize会立即复原。
6. PARTIES开销
配置PARTIES作为运行时(runtime)绑定在核心0上,占它的CPU利用率的15%(监测与资源调整分别占用10%和5%)

观察:
i. PARTIES花费数秒(当初始划分就有效时)到60多秒(遇到所有6个LC应用混布的最差情况)以收敛到一个没有QoS违规的分配,通常,收敛时间依赖于每个应用的负载,以及混布的应用的数目;
ii. 仅管总搜索空间随着混布的应用的增长而指数级增加,收敛时间实际上增长地更缓慢;
分析
这是因为PARTIES不会去寻找最优的资源分配:相反地,它在所有应用满足QoS时停止搜索,这极大地降低了搜索时间。PARTIES接着依赖Downsize()来进一步缩小当前选择的分配与最优的分配之间的差距。
三、自己的认识和体会
本文提出的资源置换性有很深远的意义,他实际上反映出一种“等价性”:我们对于某个目标,本文用QoS,我们可以设置另一个目标如IPC,它也受到多重因素的影响,应该也能找出类似的现象——调整不同核心数、LLC ways、频率,我们法相某个应用的IPC还维持再一个恒定的值,那么就能实现更灵活的资源划分机制。