
NBJL 2020论文导读14:How Much Position Information Do Convolutional Neural Networks Encode ?
论文下载地址:https://openreview.net/pdf?id=rJeB36NKvB
发表时间:2020
会议名称:ICLR
作者:Md Amirul Islam、Sen Jia、Neil D. B. Bruce
论文摘要
相对于全连接网络,卷积网络依靠有限空间内的局部连接,大幅度提高了图像处理的效率。局部连接似乎暗示了卷积过滤器虽然感知当前的内容,却不知道当前所处的位置。
绝对位置信息毫无疑问是有用的,有理由认为如果可以做到,卷积网络必然隐式地学习到了编码位置信息。在这篇文章中,基于几种常用的卷积网络,我们对该假设进行了较好的验证。详尽的实验表明了该假设的有效性,阐明了位置信息是如何及何处被卷积神经网络编码的。
论文内容
作者首先进行了一个初步的实验:

图 1 显著性物体检测发生区域偏移
图1为卷积网络进行显著性物体检测,橙黄色区域即为标识的显著性区域。第一行为原图,第二行为在原图右边剪裁掉一小部分后的图。可以看到,剪裁后标识的显著性区域发生了左移,即向图像中间靠拢。这表明卷积网络感知到了图像的中心的位置,初步表明卷积网络利用了位置信息。
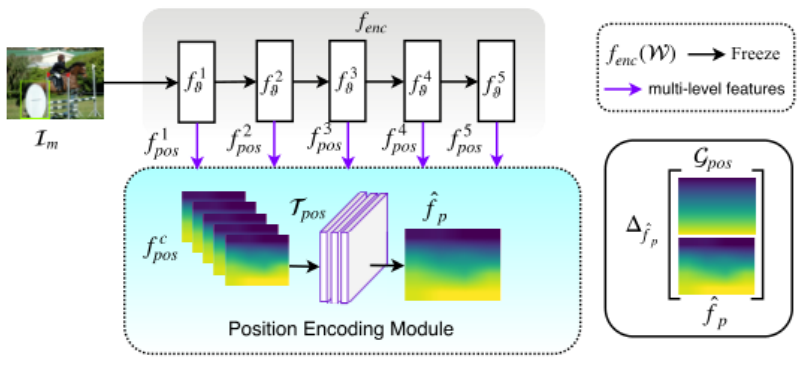
图 2 Position Encoding Network 架构
作者假设位置信息是通过卷积中的 Padding 学习到的,为验证该假设作者提出了图2中的Position Encoding Network。其中 为预训练的VGG或者 ResNet,仅作为前馈网络,其参数不参与Position Encoding Network训练。 为前馈网络的在五个卷积层产生的特征图,使用双线性插值缩放到统一尺寸进行拼接,之后输入到 Position Encoding Module 中。Position Encoding Module 为一般卷积网络,其卷积核未使用Padding。
该网络试图判别卷积网络层产生的特征图中是否含有位置信息。
该网络的输出是一个与输入特征图等高等宽的图像,该图像表示位置信息。
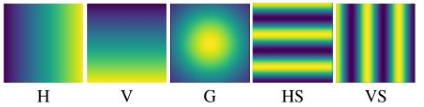
图 3 训练Position Encoding Network 的Ground Truth
图3为训练使用5种 Ground Truth,每次训练时选择其中一种,即所有样本的标签都是一样的。以H为例,如果输入的特征图中不含有水平方向的位置信息,则不可能输出这样的图案。网络损失函数为逐像素的 MSE。

图4使用不同前馈网络的输出
图4展示了一个直观的实验结果实例,竖向是分别三种 Ground Truth,横向分别是原图、Ground Truth、无前馈网络、VGG作为前馈和ResNet作为前馈。可以看出经过前馈网络编码的特征可以较好地拟合 Ground Truth,其他则不能。这表明位置信息在分类任务的卷积神经网络结构中隐式编码,无需进行任何明确的监督。
作者后续的实验发现在去除前馈网络中的 Padding操作后,Position Encoding Network无法拟合Ground Truth,证明了位置信息来源于Padding。另外的实验表明,卷积层数越多,卷积核越大,位置信息的提取能力越强。
自己的认识和体会
读完这篇论文,有两个比较意外的感受。第一,惊讶于如此基础性的内容,之前竟然没有相关研究。第二,作者的思路(包括网络构造、训练及评价指标)也比较简单。这篇论文获得了ICLR满分,并被评为Spotlight。可见,基础性的东西仍然存在研究的空间。这篇论文中,作者的研究虽然看起来简单,却非常需要对该领域较高的熟悉度。因为越是基础性的研究,越需要严谨准确的研究过程和方法。