
NBJL 2020论文导读13: High-density Multi-tenant Bare-metal Cloud
赵盛
论文下载地址:https://dl.acm.org/doi/abs/10.1145/3373376.3378507
论文信息: 本文由阿里云团队发表在2020年三月份的ASPLOS上。
论文摘要(包括论文动机、创新点或者贡献,论文的结论等)
虚拟化作为公共云服务的基础,以其丰富灵活的特性使得云服务器资源得以被高效共享。然而多用户的资源共享可能会导致严重的安全问题,同时虚拟化资源也存在不容忽视的性能开销。对此,裸金属云架构的方案虽能很好的消除安全问题和性能损失,但其较低的性价比和极差的扩展性使其难以被广泛应用。
为优化虚拟云服务技术的性能损失和加强系统安全性,本文提出了一种多用户裸金属云架构“BM-Hive”。这种架构下,云用户运行在计算子板上(独占CPU和内存资源),通过软硬件结合的virtio直接访问IO设备。此外,一台服务器可支持多块计算子板的运行,并与当前主流的虚拟化云服务兼容。目前,BM-Hive架构(即阿里神龙架构)已大规模应用至阿里云旗下的诸多系统,在实际生产环境中表现出强大的性能和稳定性,且成本较低。不仅如此,神龙还是目前最流行的容器技术的最佳拍档。基于神龙架构的阿里云容器服务对比物理机有10%-30%的性能优势。
论文内容
当前虚拟化技术的主要问题
当前主流的基于虚拟机的云服务(下文称VM-Based)主要面临以下问题
虚拟化开销不可忽视,无法满足高性能需求
虚拟化的开销VM-Exits次数直接相关,而当前虚拟化技术的原理决定了CPU需要频繁的从guest mode到物理CPU间来回切换(如中断或缺页),切换可能会消耗成百上千个时钟周期,当虚拟机每秒VM-Exits次数超过5K时会对性能产生明显影响。图1的测试采样了30万个实例每秒VM-Exit次数,结果表明超过10K次的实例占比超过3.82%,甚至还有超过100K次切换的实例存在,这会严重浪费CPU的时钟周期。
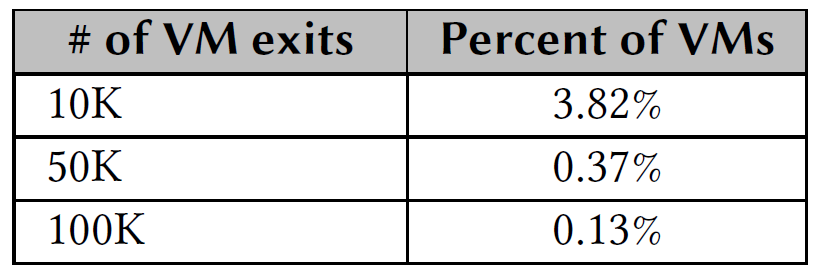
图一:单vCPU下每秒VM-Exits次数
资源竞争导致的性能抖动导致云服务性能不稳定
VM-Based架构中客户机与宿主机共享CPU资源,因此宿主服务器繁忙时,由于资源竞争导致的性能抖动可能会对客户机的运行产生影响。图2的测试采样了2万个实例(分为独占型和共享CPU型)在24小时内运行中CPU被抢占的情况。发现两组样本实例都会受到CPU抢占的影响,且共享性虚拟机CPU的抢占率最差可达到10%,性能抖动达到8%。
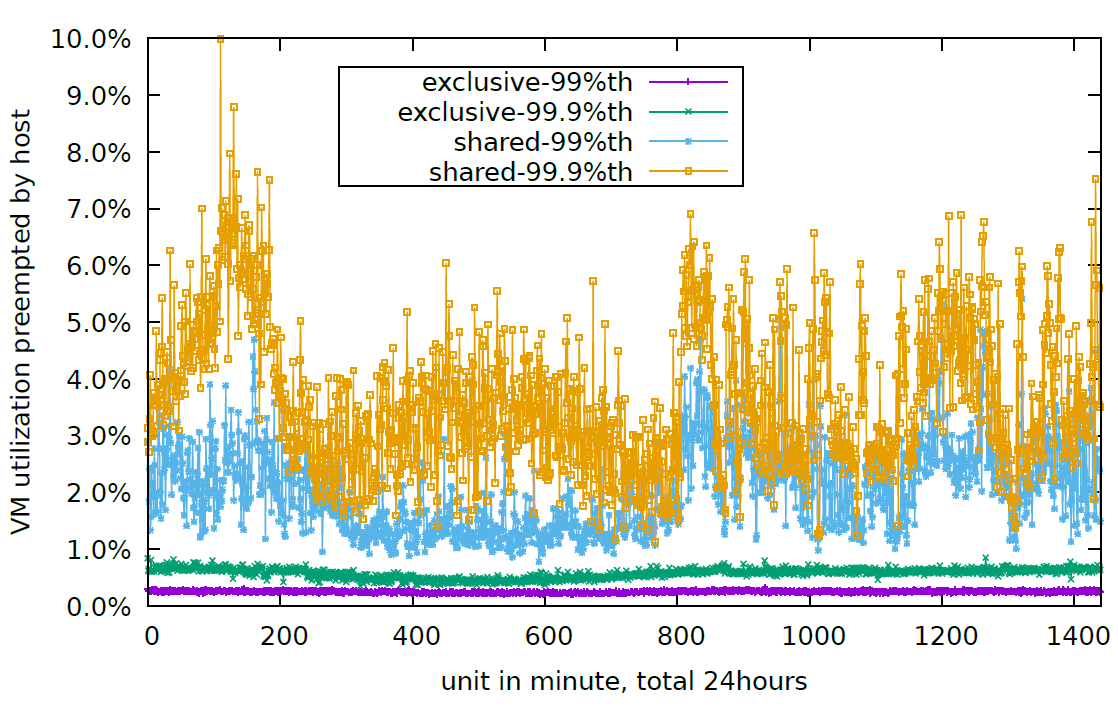
图二:性能抖动测试
虚拟化的弱隔离性存在安全性问题
虚拟机技术主要由软件提供隔离性,在硬件层面依然是共享物理资源。这种较弱的隔离可能会收到侧信道攻击(Side-Channel Attack)。云环境下这种攻击方式通过共享物理资源(cache,内存,网络)捕获额外输出信息从而达到破译敏感信息的目的。
嵌套虚拟化的性能损失较大
一般来说KVM嵌套虚拟化的性能损失在20%以上,尤其是遇到一些IO操作更频繁的场景。因此当前云计算实例上很难在满足客户二次虚拟化的要求
裸金属云架构可简单理解为物理服务器直接租赁的方案。这种情况下,客户机得以获得严格的物理隔离性和原生硬件性能。但这种完全释放服务器的控制权给云用户可能存在一定安全风险。此外,目前大部分云服务硬件配置远超普通用户所需,且多核心的服务器级CPU往往无法提供高频桌面级处理器类似的较强单线程性能。
BM-Hive架构设计
为了解决现存虚拟化技术的诸多问题,BM-Hive的设计目标为:高密度多用户,物理级别的隔离性,广泛的兼容性,原生设备性能,低成本。
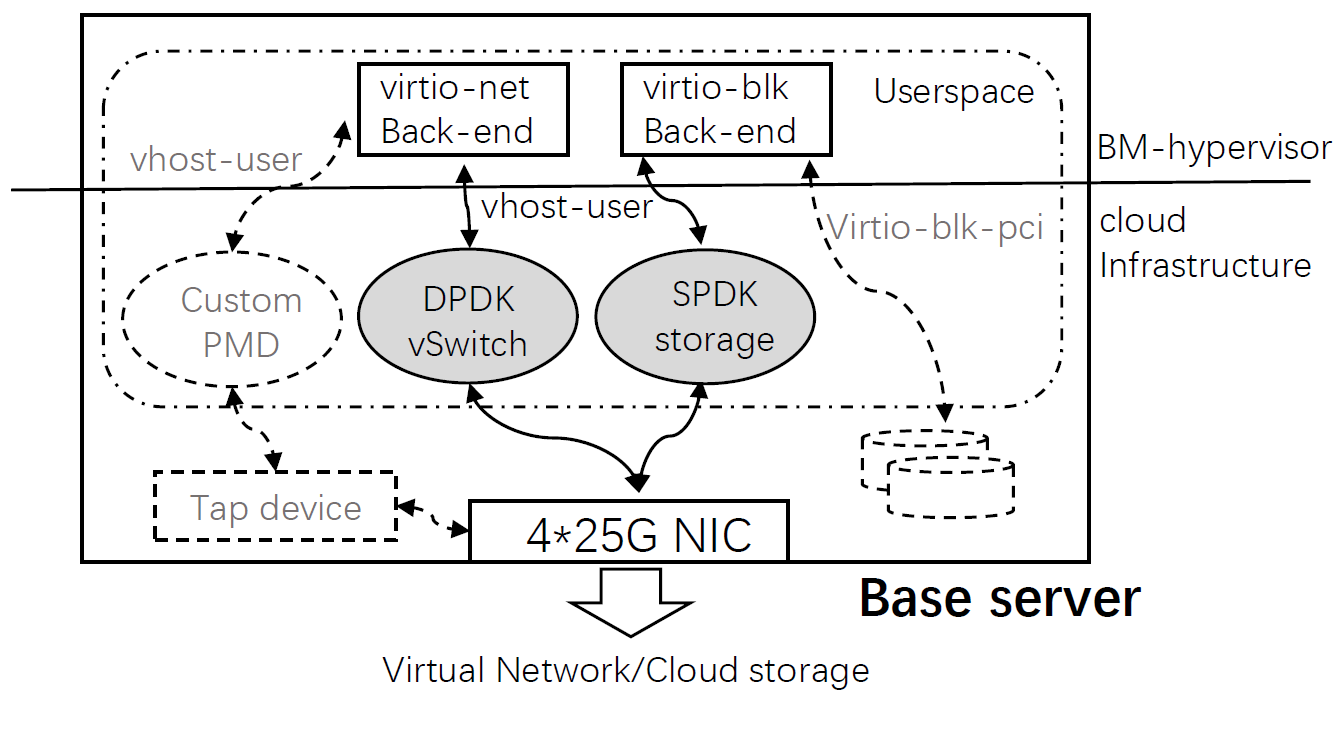
相对于VM-Based架构,BM-Hive在整体结构上的主要不同点是每个客户机都独占物理CPU和内存资源,而非物理资源的虚拟化。BM-Hive也存在管理监视器bm-hypervisor,并具备相似的virtio机制进行IO的虚拟化。
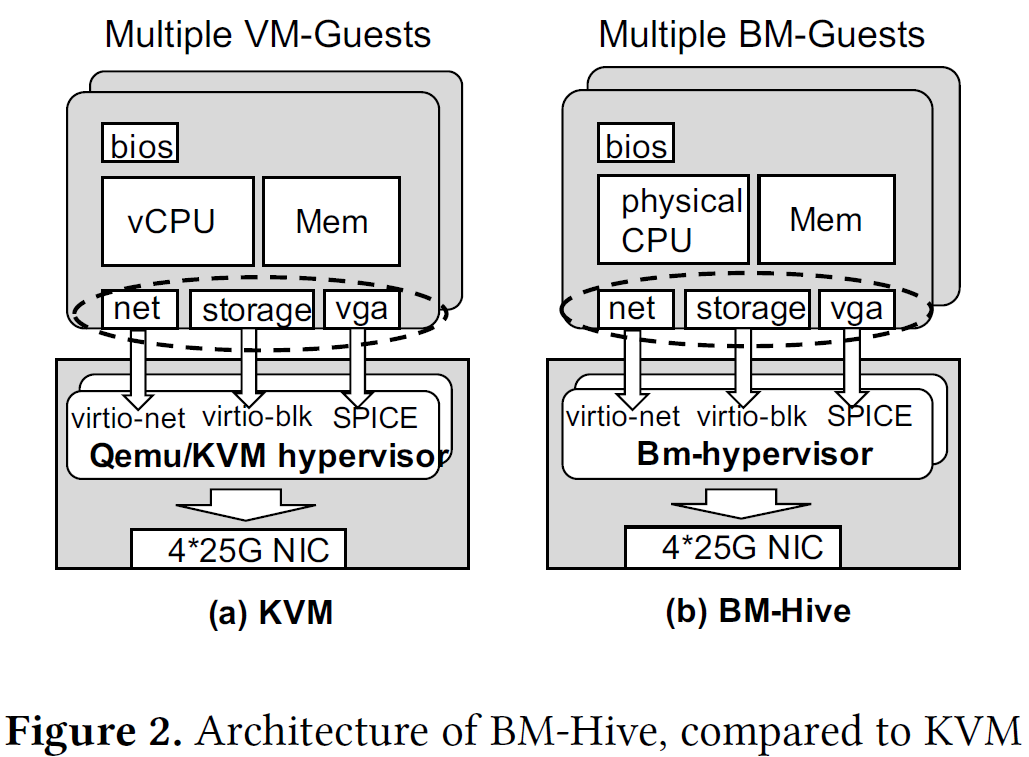
从结构设计上来讲,基于BM-Hive架构的单台服务器拥有一块主体资源板和多块计算子板。其主板本质上是一台简化的Xeon-based服务器。而计算子板通过PCIe插槽在主服务器上进行扩展。内部主要组件为独立的CPU和内存资源,PCIe总线和IO-Bond设备。当前IO-Bond由FPGA实现,分别通过PCIe总线与bm-guest和主板相连,模拟virtio设备,并充当guest和主板间交互的媒介,我理解它的意义也是为了保证子板和主板无法直接接触,实现了更好的隔离性。Bm-hypervisor扮演着管理客户的角色,与vm-hypervisor不同的是,它与客户机之间在数据交互路径上并非是严格的上下层承接关系,而更像是一种外部管理程序。此外bm-hypervisor的存在使得该架构与主流VM-Based架构得以兼容。再者,由于标准化的virtio协议机制存在,使得计算主板上的CPU可被灵活选择,仅需要兼容通信协议即可。

常规的virtio由前后端驱动组成,前端(front-end)通过指定的通知机制(如hypercalls)向后端递交I/O请求。处理结束,后端(back-end)以注入中断的方式通知前端。前后端I/O数据交互通过一个共享环形缓冲区(ring buffer)以避免不必要的内存拷贝。BM-Hive的IO-Bond设备提供了软硬件结合的virtio系统。IO-Bond同样被分为前后端。由于客户机和服务器主板间内存隔离,因此IO-Bond在两端各维护一段vring buffer,两个缓存区通过DMA进行数据同步。
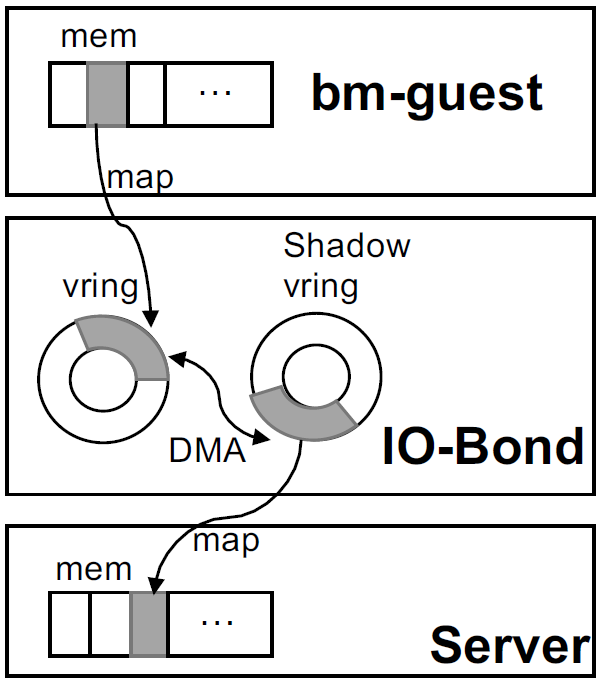
IO-Bond Backend负责接收IO请求并转发至相应云设备。I/O请求被DPDK vSwitch和SPDK处理,并采用PMD避免中断延迟。所有的处理都在用户态完成以避免额外的内存拷贝。
成本
数据中心的收益主要取决于相同空间的机架可出售的核心数(即vCPU的密度)。目前主流的VM-based服务器有两块24核(48HT)的E5 CPU,其中8HT用于hypervisor和宿主机内核。可用于云服务的有88HT。同等大小的机柜,BM-Hive可支持8个32HT的计算子板,共256HT可用于云服务。除去为每个guest添加的FPGA硬件和一个服务器主板(16HT E5 CPU),单个bm-guest成本比同配置的vm-guest仍然便宜10%。
在功耗方面,单计算子板的BM-Hive服务器(3.17Watts/per-vCPU)比VM-based服务器(3.06Watts/per-vCPU)功耗稍高,这是由于存在额外的FPGA和主板CPU的功耗开销。
性能测试
对CPU,内存,网络,存储方面对BM-Hive与传统VM-Based做对比,以及对实际业务场景的应用性能测试。
CPU和内存性能对比
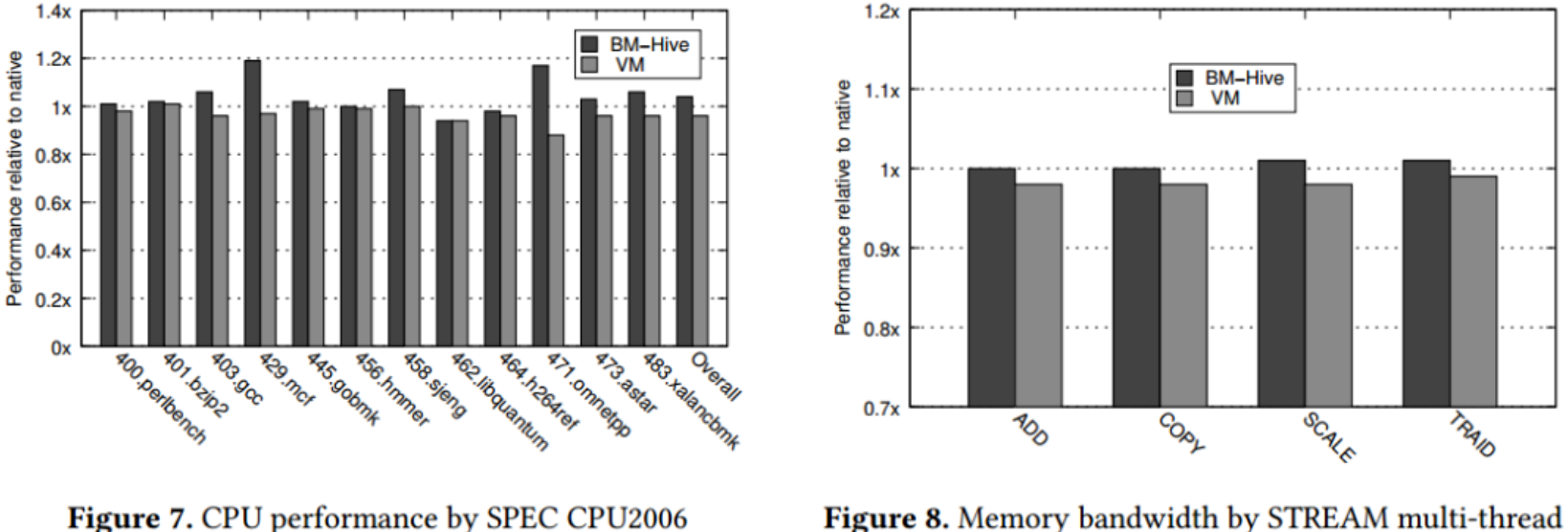
实验将BM-Hive和VM-Based实例运行在SPEC CINT 2006测量CPU性能,用STREAM工具测试内存性能,结果相对于物理机性能做了归一化处理,表明BM-Hive实例在CPU和内存性能略优于物理机,而VM-Based实例性能由一定损失。
IO性能对比
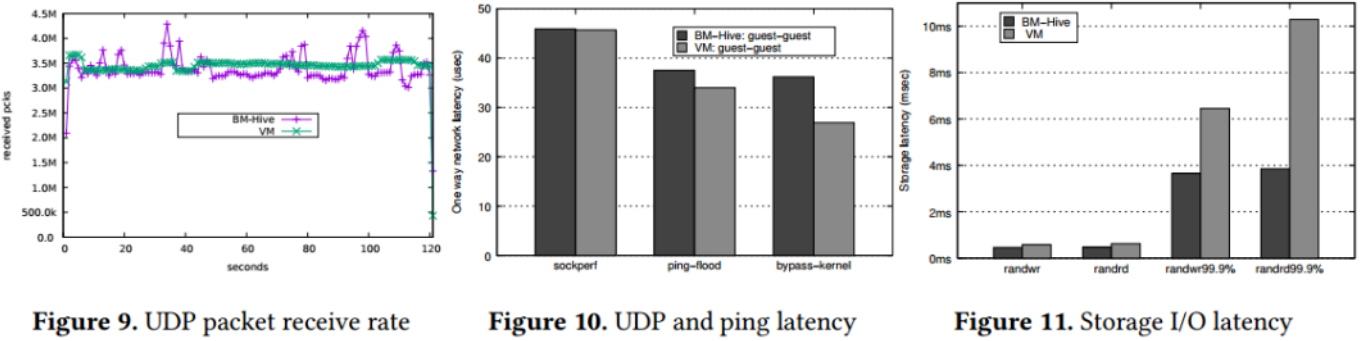
通常情况下,云环境中为了保证服务器整体性能的稳定及公平性,往往会对客户机的性能做一定限制。在测试中,两种实例产品的网络最大发包速度限定为4M PPS,带宽上限为10Gbit/s,存储限制为25K IOPS和300MBps。在网络性能方面,两者都能达到最大发包速度,但VM-guest整体性能更加稳定。原因可能在于VM-guest网络数据包在同驻客户机间的传输可直接通过内存,而同驻的BM-guest间需要多过一次BM-hypervisor,路径较长。网络延迟方面,VM-guest稍优于BM-guest。在存储性能方面,BM-guest的长尾延迟性能明显优于VM-guest,在不限制存储性能时,BM-guest更是比VM-guest吞吐量高50%,带宽高100%,这可能是因为BM-Hive通过DMA直接拷贝给相应块设备,而VM-guest需要CPU进行额外的内存拷贝。
应用性能测试
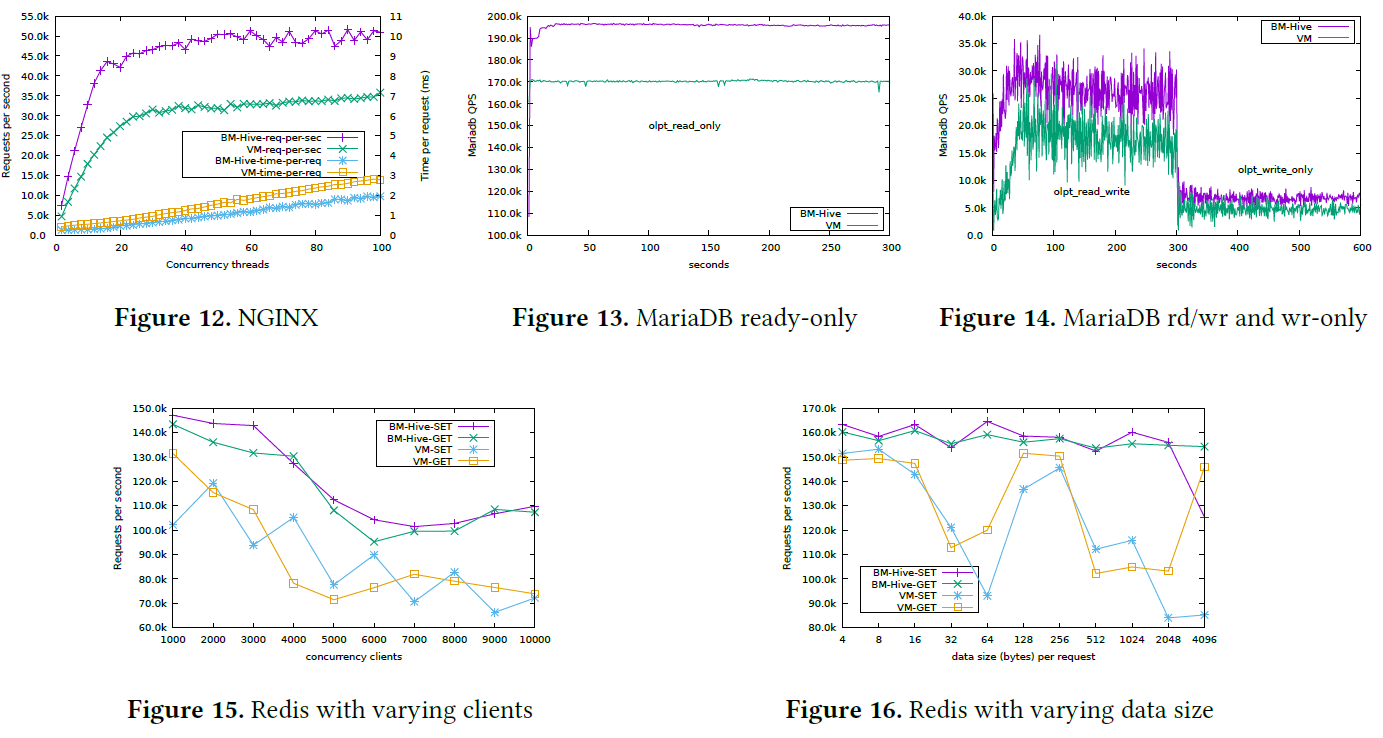
实验对比了两种实例在网络服务器nginx,数据库mariaDB和内存数据库Redis见的性能差异,BM-Hive架构均有明显的性能优势。
自己的认识和体会(包括与自己工作的联系和启发等)
文章着眼的性能开销及安全风险是虚拟化技术普遍存在的问题,而裸金属架构有效的解决这两方面的问题,文章所提出的BM-Hive架构是对裸金属架构的优化及扩展,使之能兼容主流的VM-Based云架构。这种软硬件结合的云服务可能是虚拟化技术未来的发展趋势。目前我的工作主要进行软件层面的优化,这种软硬件结合的IO策略为日后的研究拓宽了思路。