
NBJL 2020论文导读11:An Empirical Guide to the Behavior and Use of Scalable Persistent Memory
论文(以及slide)下载地址:
论文:https://www.usenix.org/system/files/fast20-yang.pdf
Slide:https://www.usenix.org/sites/default/files/conference/protected-files/fast20_slides_izraelevitz.pdf
论文信息:
发表时间:2020年25~27日,发表在FAST 2020上,作者信息如下:
Jian Yang, Juno Kim, and Morteza Hoseinzadeh, UC San Diego;
Joseph Izraelevitz, University of Colorado, Boulder; Steve Swanson, UC San Diego
论文摘要
文章从微观和宏观角度探讨了英特尔新型Optane DIMM的性能和特性。首先,研究设备的基本特性,特别注意其性能相对于传统DRAM以及过去用于模拟NVM的方法。根据这些观察结果,文章提出了一套最佳实践,以最大化设备的性能。随后探索并重新优化了应用程序级软件中用于持久性存储的现有技术。
主要内容:
文章首先介绍了Optane的相关背景,包括硬件保障、访问流程、持久性保障、访问模式、有关指令集等内容。下图为Optane访问流程:
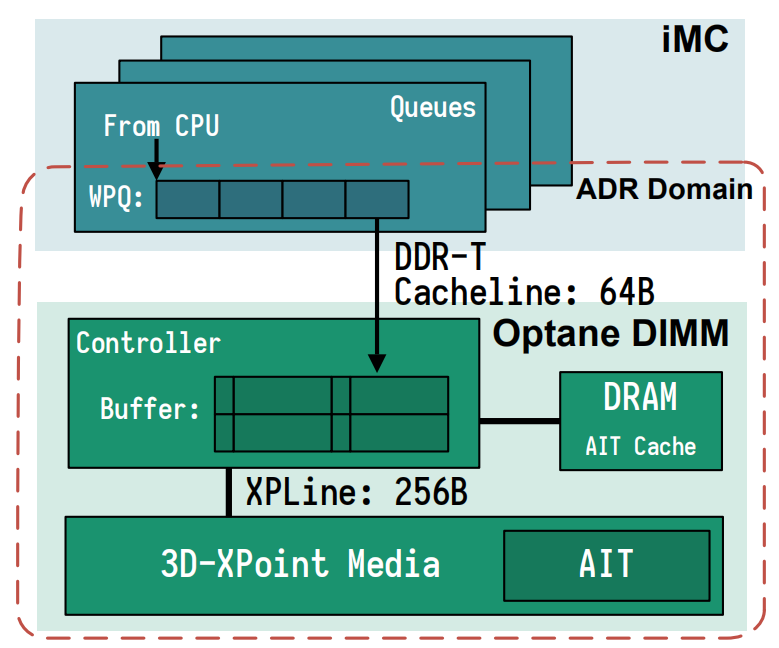
对Optane行为分为两部分进行研究:一是系统数据测试,对Optane配置参数进行了广泛系统的测试,包括访问模式(随机与顺序),操作指令,访问大小,步幅大小,功耗预算,NUMA配置以及地址空间交错。带宽测试需要简单进行说明,
随机访问粒度小于256 B会造成Optane带宽较差,瓶颈对应于XPLine(256B)的大小。对于交错式进一步增加了复杂性:测量六个交错NVDIMM的带宽,是单个NVDIMM的带宽5.8倍和5.6倍。是和系统中DIMM的数量相匹配的,需要说明的是,访问粒度4kB时的性能下降,是因为当线程执行接近交织大小的随机访问时,将会最大化iMC上的竞争。

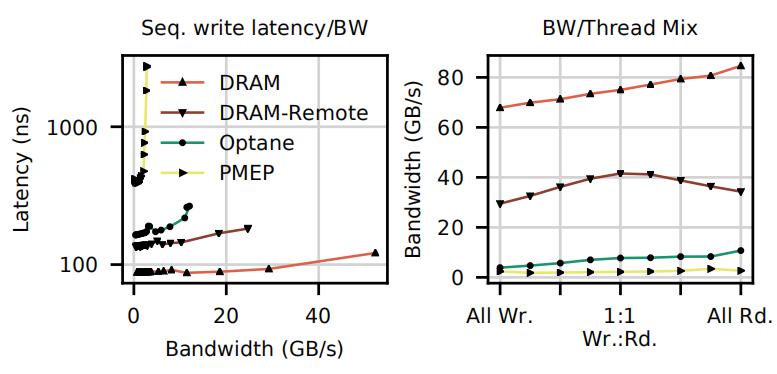
二是后续针对实验,利用这些数据,设计了有针对性的实验,以调查异常并验证有关假设。左图是NVM仿真机制与实际Optane内存相比的顺序写入延迟/带宽曲线。右图是相对于读/写线程数的带宽(所有实验都使用固定数量的线程)
这些图中的数据表明,没有任何一种仿真机制能够捕获Optane行为的细节,所有方法都与实际的Optane内存大不相同。
最后文章将实验表征的结果提炼为四个原则,以建立和调整基于Optane的系统:
原则1:避免小的随机访问(实例研究:RocksDB&NOVA)
原则2:对于大型写入使用nt-store(实例研究:对PMDK做微缓冲优化)
原则3:限制访问特定Optane DIMM的并发线程数(实例研究:Multi-NVDIMM NOVA)
原则4: 避免对远程NUMA节点进行混合或多线程访问(实例研究:PMemKV)
自己的认识和体会
在Optane内部以256字节粒度更新,这就意味着较小的更新会导致效率低下,因为它们需要DIMM执行内部读-修改-写入操作,从而导致写入放大,要尽可能地去贴合256字节,避免写放大。
store + clwb会将数据加载到CPU的本地高速缓存中,从而耗尽部分Optane DIMM读带宽。随着ntstore绕过缓存,它们将避免这种不必要的读取,并可以实现更高的带宽。
随着访问大小的增加,线程竞争更加频繁地发生,应尽可能避免以交织大小(4 kB)的粒度进行访问,防止带宽的突然下降。