
NBJL 2020论文导读9: Deep Forest
牛志衡
论文下载地址:https://arxiv.org/pdf/1702.08835
发表时间:2019
刊物:National Science Review
作者:Zhi-Hua Zhou,Ji Feng
论文摘要
本文首先介绍了当前深度学习模型大多是建立在神经网络的基础上,通过反向传播训练参数可微。然后提出了一种基于
可微的树模型,gcForest。与神经网络在逐层处理、模型内转化和足够的模型复杂度不同,深度森林使用更少的超参数,并且模型对于来自不同领域的不同数据也能够获得出色的性能。深度森林为解决不可微模块构造深层模型提供了可能性
论文内容
提出训练DNN时存在的问题:
1.训练DNN时,由于存在庞大的超参数(hyper-parameters),导致模型训练后的表现依赖于参数优化。同时,由于众多因素的干扰,训练所得的DNN模型理论分析会很难,模型可解释性很差。
2.DNN训练时需要大量的训练数据,小规模训练得出的模型并不具有很好的实用性。所以得到大量的带有标签的数据也是一个庞大的任务。
3.设计神经网络之前,我们需要提前确定模型的结构,当然这个过程一般是凭个人经验或前人的工作,以及大量的试错。任何的事物都是具有变化性的,所以用预先确定好的模型结构去得出的结论可能会是自己需要的,但是真的具有可靠的理论基础,难以把握。
提出的解决方案:
基于神经网络成功的原因:层与层的处理、模型内特征转换、足够的模型复杂度,提出了基于决策树模型的深度森林模型,模型在更少的参数下,建立在
可微的基础上,不需要进行反向传播,能够达到神经网路同样的效果。
深度森林模型解析:
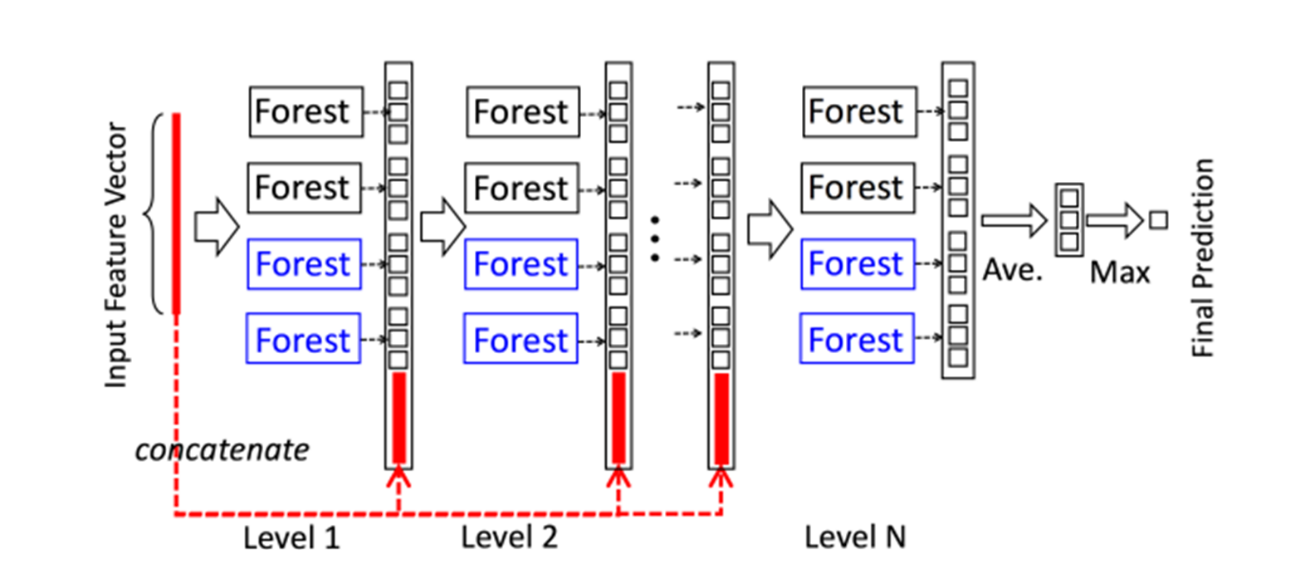
级联森林结构
级联结构中,每一层的级联接收前一层处理的特征信息,并将处理结果输出到下一层,每一层都由多个随机森林组成。通过随机森林学习输入特征向量的特征信息,经过处理后输入到下一层。为了增强模型的泛化能力,每一层选取多种不同类型的随机森林,上图给了两种随机森林结构,分别为completely-random tree forests(蓝色)和random forests(黑色),每种两个。其中,每个completely-random tree forests包含500棵树,每个节点通过随机选取一个特征作为判别条件,并根据这个判别条件生成子节点,直到每个叶子节点只包含同一类的实例而停止;每个random forests同样包含500棵树,节点特征的选择通过随机选择√d个特征(d为输入特征的数量),然后选择基尼系数最大特征作为该节点划分的条件
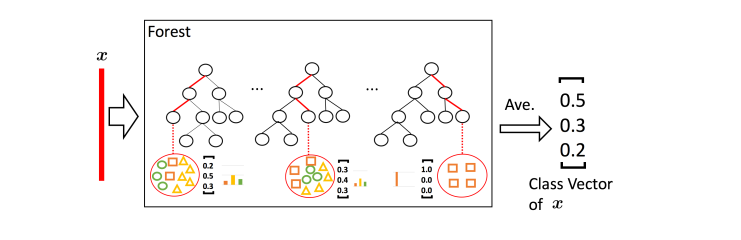
计算模式
以三分类为例,输入特征为向量x,经过每棵树计算后,得到类分布,然后通过求平均,得到当前森林的输出。经过多个森林的叠加作为增强特征,输入到下一层中。
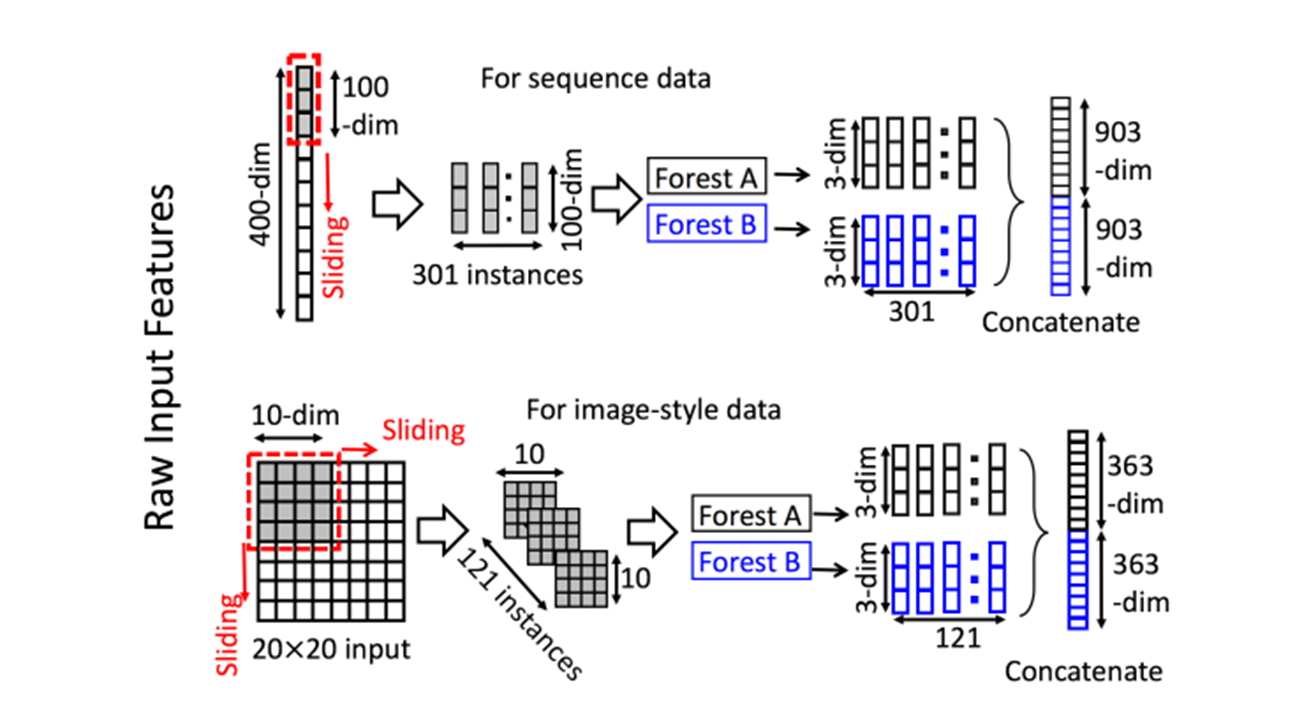
特征处理
通过多粒度扫描,滑动窗口用于扫描原始特性,然后拼接生成生成输入特征
深度森林的整体架构:
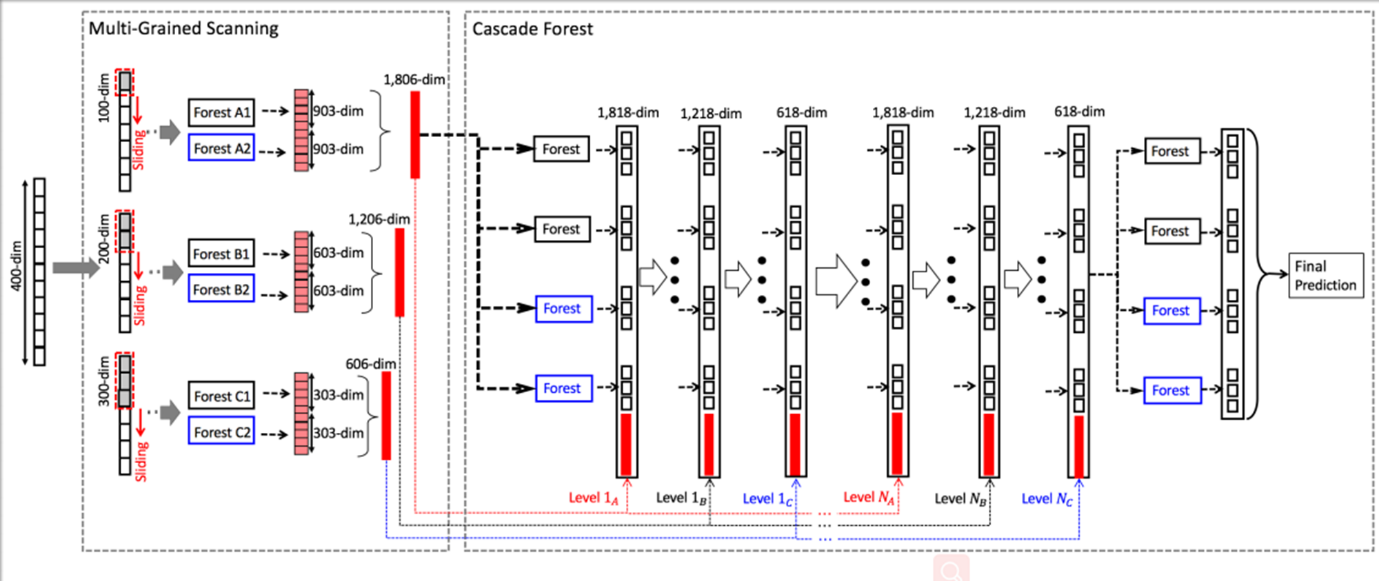
图一

图二
图一和图二展示了深度森林的整体结构,原始的输入特征经过多粒度扫描处理后,生成输入特征,然后输入到设计好的级联森林结构中,级联结构可以通过判定是否达到目标要求以确定是否生长。其中图一和图二主要区别是经过不同粒度扫描的结果在生成级联输入特征时是否进行合并。
自己的认识和体会
深度森林在调参上具有一定的优势,训练简单,结构更加容易理解,在处理小规模数据上有一定的优势。
深度森林相比于深度神经网络在图像、语音等经典领域还是存在劣势,这种基于树的方法造成树与树之间结合度不够高,并且对输入特征的处理也存在复杂性。