
NBJL 2020论文导读7:Arachne Core Aware Thread Management
刘浩源
论文信息:
论文地址:https://www.usenix.org/conference/osdi18/presentation/qin
发表时间:2018
会议名称:OSDI
作者:Henry Qin, Qian Li, et al.
论文摘要:
本文是斯坦福大学Henry Qin小组的工作,实现了一个用户级线程调度方案(Arachne),它能依据负载对应用的线程进行CPU核心的调度,使得特定的应用程序(线程生存周期短)同时保持低延迟和高吞吐量。作者使用Memcached和RAMCould进行验证,使得Memcached提高了37%的吞吐量,同时降低了10倍的尾延迟,使得RAMCould增加了2.5倍以上的写吞吐量。项目代码开源在了Github上。
论文主要内容:
问题的提出:
传统的线程调度时,会为应用的每个请求创建一个内核线程,将应用进程在CPU上进行调度,这样导致系统资源利用率低下,而且会造成应用程序之间的资源的竞争。
作者解决方案:
提出Arachne,让应用程序“知道”自己所需的CPU核心数,并独占核心,为每个核心创建的一个内核进程,消除与其他应用的资源竞争,最后对应用程序的线程依据负载在CPU核心上进行调度,以优化应用的性能。
本文创新点:
1.Arachne在应用程序运行时会估计所需CPU核心数量。
2.Arachne允许每个应用程序定义一个core policy,在运行时按照policy确定应用程序需要多少核心,以及如何在可用核心上放置线程。
3.Arachne旨在最小化Cache-miss。它使用了一种新的调度信息的新表示形式,为线程创建,调度和同步提供了低延迟和可扩展的机制。
4.Arachne为每个CPU核心创建一个内核线程,比传统的为每个请求创建一个内核线程更加灵活。
5.Arachne是用户态实现,不需要修改内核。Arachne应用程序可以与不使用Arachne的传统应用程序共存。
Arachne架构:
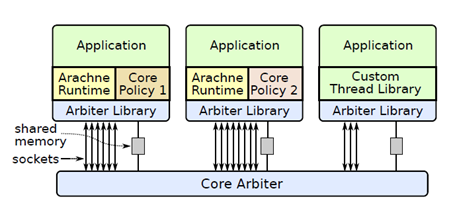
Arachne由三部分组成:Arachne runtime、core policy、core arbiter。Arachne runtime是连接到应用程序上的库,负责创建内核线程,应用程序性能的采集,以及应用线程的创建,删除等操作。core policy是连接到应用程序上的库,主要负责根据收集到的性能信息,决定应用所需CPU核心数以及进程应该被分配到哪些核上,core arbiter通过cpuset实现,主要负责CPU核的分配。应用进程与core arbiter通过socket和share memory page进行通信。
Arachne运行过程:
1.启动Arachne Runtime获取应用初始所需核心数,通过core arbiter将CPU和分为managed cores(运行Arachne应用)和unmanaged cores(运行其他应用)。
Arachne runtime为每个CPU核心创建一个内核线程,并阻塞应用其他的内核线程。
2.当应用运行时,对应用新产生的线程,在managed cores中随机选择两个核,并将应用放到线程数目少的核上。
3.运行时,时刻监视系统性能,主要通过Arachne runtime测量两个指标:1)utilization,指的是每个核上执行用户进程的平均时间。2)runnable threads,指的是每个CPU核心上用户进程的平均数量。
4.根据Arachne Runtime测量的数据,core policy产生进行分配与回收CPU核心的策略,通过core arbiter进程对应的操作,这里注意,CPU核回收时并不是直接抢占CPU核心,而是在share memory page中放入等待变量,等待应用响应,若超时未响应,再强制回收。CPU核心的分配条件是Runnable Threads大于某个阈值,回收条件是utilization小于上次分配核心时的值。
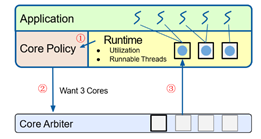
CPU核心分配过程
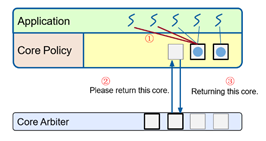
CPU核心回收过程
保持低cache-miss的方法:
Arachne由于跨核通信,可能会产生大量cache-miss,cache-miss的高低是衡量Arachne性能的关键,文章使用以下方法降低cache-miss:
1.在应用线程创建阶段,将线程的许多操作并行执行,例如创建线程与分核操作。
2.在应用线程调度阶段不使用runnable queue,而是对当前核相关的所有线程进行扫描,直到找到一个可以运行的线程为止。
论文存在的问题:
1.只是对线程CPU核心进行调度,并没考虑到其他系统资源,如LLC。
2.本文没有考虑机器的异构性,和应用程序的多