
NBJL 2020论文导读2:Pangolin: A Fault-Tolerant Persistent Memory Programming Library
耿英杰
https://www.usenix.org/conference/atc19/presentation/zhang-lu
论文发表于2019年USENIX Annual Technical Conference(ATC)中,出自加州大学圣地亚哥分校的Non-Volatile Systems Laboratory(NVSL)。该实验室专注于新型内存技术的研究,近年来在ATC、FAST、ASPLOS等A类会议发表多篇高水平论文,包括基于非易失性内存的测试框架、文件系统、编程库等多个方向。
非易失性内存(NVMM)的一个重要特征就是支持DAX模式,在该模式下,实现崩溃一致性(Crash consistency)和容错(Fault tolerance)都十分必要,近年来已经有诸多实验团队针对Crash consistency提出解决方法,但对于Fault tolerance的研究还比较稀少。在这样的背景下,论文提出了一种能实现fault tolerance的,基于DAX-map的NVMM编程库——Pangolin,用于应用程序在NVMM中构建复杂的数据结构。Pangolin结合了校验和(checksum)、奇偶校验(parity)和微缓冲(micro-buffer)三种技术,能够同时避免media error和software bug带来的损害,并支持自动检测和在线恢复。与现阶段支持fault tolerance的NVMM编程库相比,Pangolin使用了的很小的存储开销,达到了类似的性能。
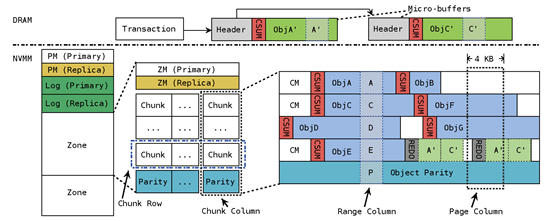
对于一个NVMM pool,其中pool和zone的元数据PM和ZM,以及Log区域仍然采用replication的方式进行容错,因为这一部分所占的存储空间很小(对于1GB的pool,只占用0.1%的存储空间)。对于chunk区域,在逻辑上将其组织为二维数组的形式,最后一行作为parity data进行奇偶检验,chunk的元数据CM和object data都通过parity来进行数据容错。同时,Pangolin还在每个object header中开辟了32 bit的区域存放checksum,进行object data的错误检测。
为了降低更新checksum和parity所带来的的一致性挑战,Pangolin引入了micro-buffer。当需要修改一个PMEM中的object时,需要在micro-buffer中做一个object的shadow copy,对object的修改将在DRAM中进行,修改完成后重新计算checksum,将checksum和修改操作记录到Log中,随后进行parity的更新操作,当以上步骤都完成以后,将修改后的object写回PMEM中。一次完整的流程如下图所示:

采用micro-buffer除了可以降低更新一致性的复杂性以外,还可以避免缓冲区溢出,悬垂指针等软件bug对NVMM带来的影响。同时,由于micro-buffer位于DRAM中,可以借鉴一些内存调试工具的思想来实现更强的数据保护,例如,Pangolin在每个micro-buffer的header中插入了一个64-bit的canary,在将object写回之前,通过验证其完整性提供对NVMM的保护。
由于XOR运算的可交换性,在进行parity更新时,可以实现较为简单的增量更新,单个object的修改带来的parity更新过程如下图所示:
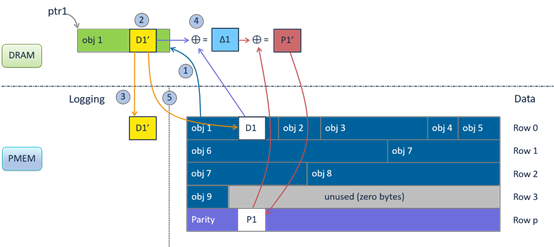
当一个Range Column中的多个object同时进行更新时,就带来了parity update的一致性挑战,同时由于Atomic XOR要慢于Vectorized XOR,为了保证更新一致性同时兼顾计算效率,论文引入了一种细粒度锁——parity range-locks。对于Small updates (< 8KB),共享range-lock,采用atomic XOR instructions并行更新parity;对于Large updates (≥ 8KB),独占range-lock,采用Vectorized XOR串行更新parity。
与libpmemobj的replication方式相比,Pangolin使用更小的存储空间实现了类似的性能,同时保证了crash consistency,除此之外还支持software级别的错误检测和在线恢复。但在容错度方面,Pangolin仅支持任意位置的单4KB page的错误,或者位于不同Range Column的object错误,这是由parity本身的性质导致的,为了提高容错度,就需要减少行数,增加列数以减少错误overlap的概率,但过多的列数同样会增加计算parity的开销。除此之外,Pangolin仅支持多线程同时修改不同的object,不支持多线程同时修改同一个object,这同时也是libpmemobj存在的问题。
Pangolin将metadata与data分离,分别采用replication和parity的方法进行容错,与现阶段工作基础,上交IPADS实验室发布的Cocytus在思想上有相似之处,论文提到的诸多实现细节,有很大的借鉴意义