
NBJL 2020论文导读25: Concurrent Data Structures with Near-Data-Processing: an Architecture-Aware Implementation
赵昌健
论文(以及slide)下载地址:https://jiwon-choe.github.io/
论文信息: 论文发表在SPAA2019,作者是来自Brown University的Jiwon Choe 等人。
论文摘要
内存体系结构的最新进展引起了新的关注,研究者希望通过近数据处理(NDP)技术来缓解“内存墙”问题。 NDP架构将逻辑电路(simple core)放置到紧挨着内存的地方。高效的使用NDP体系结构需要重新考虑数据结构及其算法。前人的工作提供了基于经验评估的并发数据结构的设计,例如有序链表、跳跃表和FIFO队列。经过模拟器级实验分析表明,前人所设计的数据结构效果并没有理论分析的那么高效,原因是前人没有考虑DRAM层面具体的硬件操作。论文对并发数据结构场景下的DRAM底层活动进行了分析,同时对DRAM内存控制器进行了轻量级的修改,提高了基于NDP的并发数据结构的性能并降低了能耗,并且在大部分情况下,基于NDP架构设计的并发数据结构性能要优于基于HOST架构的并发数据结构。
论文内容
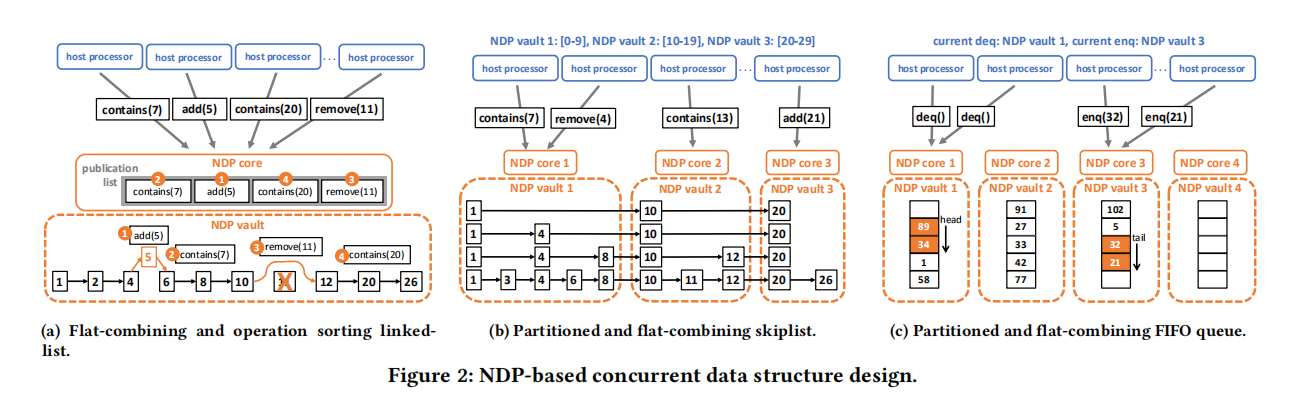
上图a、b、c分别为前人工作中NDP架构下并发有序链表、跳表、队列的具体设计,对于有序链表,多个host processor会发送请求到NDP core,由NDP core维护一个操作list,list中的具体操作由NDP core来完成;对于跳跃表,每一个NDP vault会存储对应key范围的node,host processor发送对应的请求到不同的vault,由NDP core来执行相应的访存请求;对于队列,host processor会提前知道队首和队尾处于的vault,host processor发送对应的请求到不同的vault,由NDP core来执行相应的访存请求。
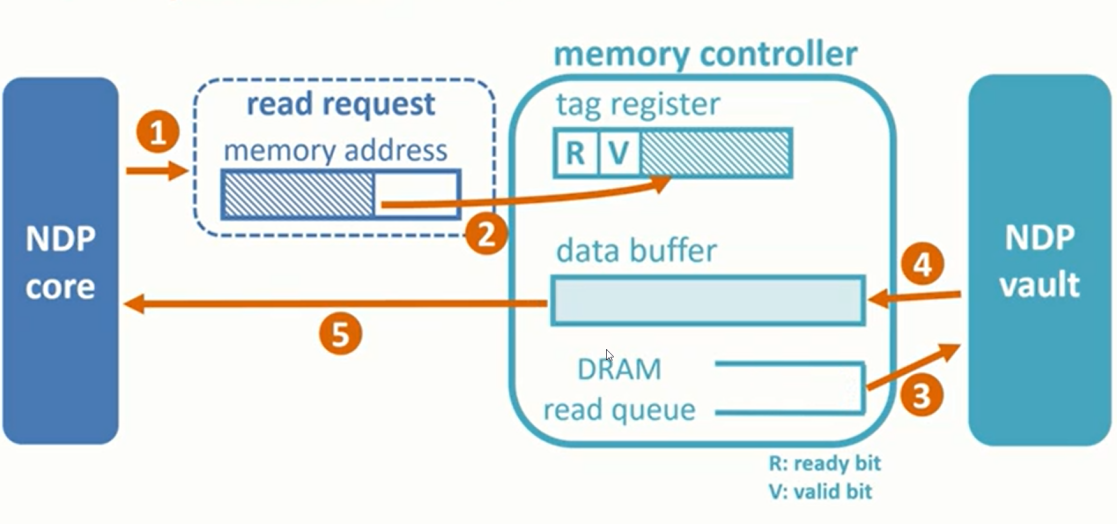
论文对NDP中的内存控制器进行了修改,主要思想是,增加buffer,提高数据复用率,减少向vault发送请求的机会;新的设计在内存控制器中添加了两部分:tag register和data buffer,分别来存储buffer中数据的地址和数据,每次有访存请求时,会先访问tag register查询当前访问数据是否存储在Buffer中,如果tag register中的地址和访存地址一致,则直接返回data buffer中的数据,否则,访问vault中的数据。
三、自己的认识和体会(包括与自己工作的联系和启发等)
论文对并发数据结构的底层DRAM activity进行分析,通过对硬件的轻量级改动,实现了高效的并发数据结构。论文中实现的数据结构为较为简单,没有涉及到cross vault access,未来可考虑复杂数据结构例如B+树如何在NDP架构下实现高效的并发。